先说结论:
Swgger 3.0 与Swagger 2.0 区别很大,Swagger3.0用了最新的注释实现更强大的功能,同时使得代码更优雅。
就个人而言,如果新项目推荐使用Swgger 3.0,对于工具而言新的一定比旧的好;对接于旧项目原有Swagger 2.0版本不变就不要变,因为它作为辅助功能能达到你的需求就可以了(当然我一再声明这只代表我的个人看法,欢迎留言讨论)。
一、Maven配置方面差异
Swagger 2.0
<!-- swagger -->
<dependency><groupId>io.springfox</groupId><artifactId>springfox-swagger2</artifactId><version>2.8.0</version>
</dependency>
<dependency><groupId>io.springfox</groupId><artifactId>springfox-swagger-ui</artifactId><version>2.8.0</version>
</dependency>Swagger 3.0
<dependency><groupId>org.springdoc</groupId><artifactId>springdoc-openapi-starter-webmvc-ui</artifactId><version>2.3.0</version>
</dependency>配置application.yml 或者application.properties
application.yml
spring:mvc:pathmatch:matching-strategy: ant_path_matcherapplication.properties
spring.mvc.pathmatch.matching-strategy= ant_path_matcher二、配置类区分
Swagger 2.0
@Configuration
@EnableSwagger2
public class SwaggerConfig {@Beanpublic Docket createRestApi(){// 添加请求参数,我们这里把token作为请求头部参数传入后端ParameterBuilder parameterBuilder = new ParameterBuilder();
// List<Parameter> parameters = new ArrayList<Parameter>();
// parameterBuilder.name("token").description("令牌")
// .modelRef(new ModelRef("string")).parameterType("header").required(false).build();
// parameters.add(parameterBuilder.build());
// return new Docket(DocumentationType.SWAGGER_2).apiInfo(apiInfo()).select()
// .apis(RequestHandlerSelectors.any()).paths(PathSelectors.any())
// .build().globalOperationParameters(parameters);return new Docket(DocumentationType.SWAGGER_2).apiInfo(apiInfo()).select().apis(RequestHandlerSelectors.any()).paths(PathSelectors.any()).build();}private ApiInfo apiInfo(){
// return new ApiInfoBuilder()
// .title("Kitty API Doc")
// .description("This is a restful api document of Kitty.")
// .version("1.0")
// .build();return new ApiInfoBuilder().build();}}Swagger 3.0
@Configuration
public class OpenAPIConfig {/*** 这个方法可以不配置会自动去扫描,但配置了更好,因为扫描有了目标性会更快* 这个方法是创建分组* @return*/@Beanpublic GroupedOpenApi publicApi() {String[] paths = {"/**"};String[] packages = {"com.example.test.controller"};//扫描的路径return GroupedOpenApi.builder().group("public").pathsToMatch(paths).packagesToScan(packages).build();}@Beanpublic OpenAPI openAPI() {return new OpenAPI().info(new Info().title("接口文档标题").description("SpringBoot3 集成 Swagger3接口文档").version("v1")).externalDocs(new ExternalDocumentation().description("项目API文档").url("/"));}
}三、常注解差异
| 注解位置 | Swagger 2.0 | Swagger 3.0 |
|---|---|---|
| Controller 类 | @Api | @Tag(name="接口名",description="接口描述") |
| Controller 方法 | @ApiOperation | @Operation(summary =“接口方法描述”) |
| @ApilmplicitParams | @Parameters | |
| Controller 方法上 @Parameters 里 | @ApiImplicitParam | @Parameter(description=“参数描述”) |
| Controller 方法的参数上 | @ApiParam | @Parameter(description=“参数描述”) |
| @ApiIgnore | @Parameter(hidden = true) 或 @Operation(hidden = true) 或 @Hidden | |
| DTO类上 | @ApiModel | @Schema |
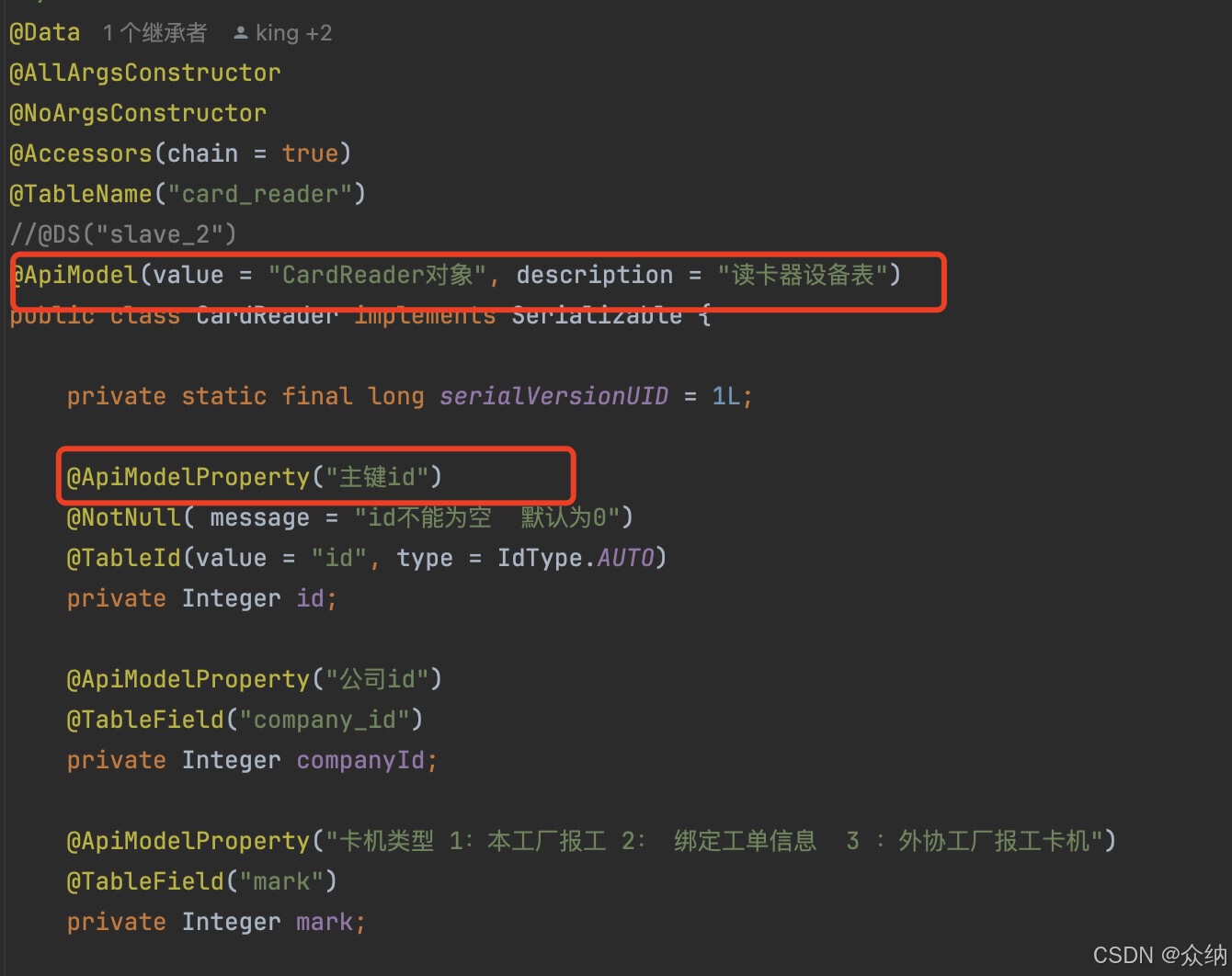
| DTO属性上 | @ApiModelProperty |
Swagger 2
controller代码

DTO
Swagger 3
Controller代码
@RestController
@Tag(name = "TestController",description = "测试接口")
@RequestMapping(value = "/swaggertest")
public class TestController {@Operation(summary = "测试接口",description = "测试接口")@GetMapping(value = "/noHiddenApi")public String noHiddenApi(@Parameter(name = "id",description = "这个ID代表.......") Integer id){return "noHiddenApi";}
}DTO代码
@Schema(description = "用户实体类")
public class SysUser {@Schema(description = "用户id")private Integer id;@Schema(description = "用户名")private String username;@Schema(description = "密码")private String password;}后记
花了近一个小时的时间写这个文章,如果有问题请留言指正,确对您有帮助请点赞收藏,谢谢观看。





