每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领域的领跑者。点击订阅,与未来同行! 订阅:https://rengongzhineng.io/

2024年11月24日,Neural Magic 推出了最新工具 LLM Compressor,这是一款专为大型语言模型(LLM)设计的优化工具库。通过先进的模型压缩技术,它能显著提升推理速度,旨在为深度学习社区提供高性能的开源解决方案,尤其适配 vLLM 框架。

LLM Compressor 解决了此前模型压缩工具分散的问题。用户过去需要分别使用 AutoGPTQ、AutoAWQ 或 AutoFP8 等多个独立库来完成不同压缩算法的任务,这让应用过程变得复杂。而 LLM Compressor 将这些分散工具整合为一个库,支持应用最先进的压缩算法,如 GPTQ、SmoothQuant 和 SparseGPT。这些算法不仅降低了推理延迟,还能在高精度要求的生产环境中维持模型的性能。
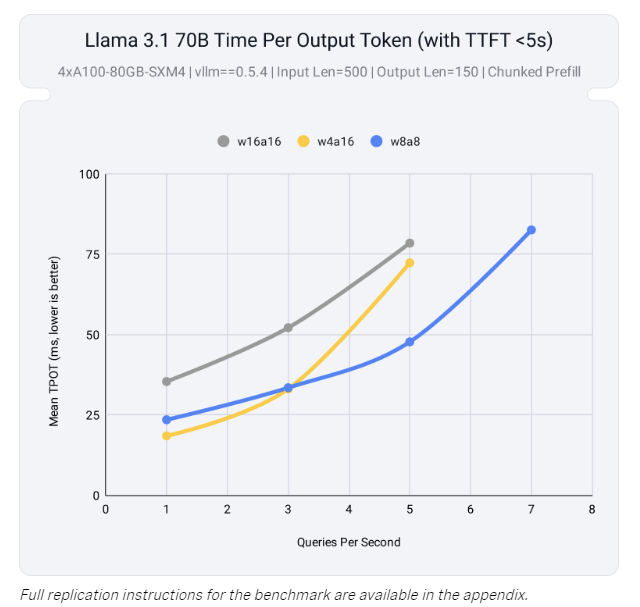
这款工具的一大技术突破在于对 激活和权重量化 的全面支持,特别是在 INT8 和 FP8 张量核心上的优化。通过量化权重和激活,LLM Compressor 能有效利用 NVIDIA 新一代 GPU(如 Ada Lovelace 和 Hopper 架构)的高性能计算单元,从而缓解计算瓶颈。在实际测试中,模型 Llama 3.1 70B 使用 LLM Compressor 后,仅用两块 GPU 就达到了未压缩模型在四块 GPU 上的接近性能,大幅提升了推理效率。
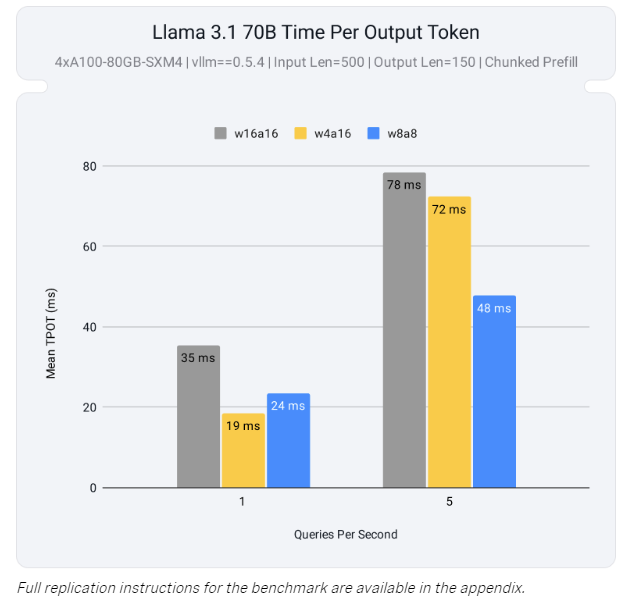
除此之外,LLM Compressor 支持 结构化稀疏性,例如通过 SparseGPT 实现的 2:4 权重剪枝技术。该方法通过选择性移除冗余参数,使模型大小减少50%,在加速推理的同时最大限度地保持精度。量化与剪枝的结合不仅降低了内存占用,还为资源受限的硬件部署提供了可能。
值得一提的是,这款工具与 Hugging Face 模型库无缝集成,用户可以轻松加载和运行经过压缩的模型。此外,它支持多种量化策略,包括逐张量(per-tensor)和逐通道(per-channel)的权重量化,以及逐张量和逐标记(per-token)的激活量化。这样的灵活性让 LLM Compressor 能够根据不同部署需求调整性能与精度的平衡。
未来,Neural Magic 计划进一步扩展工具功能,包括支持专家混合模型(MoE)、视觉语言模型和非 NVIDIA 硬件平台。同时,他们还计划开发更先进的量化技术(如 AWQ)和非均匀量化方案,进一步提升模型的效率。
LLM Compressor 的发布,标志着大语言模型优化的一次重要进步。它不仅让模型推理性能大幅提升,还降低了硬件需求,为生成式 AI 在更多领域的应用铺平了道路。这款工具无疑将成为研究者和工程师优化 LLM 部署的重要利器。


![[Unity Demo]从零开始制作空洞骑士Hollow Knight第二十集:制作专门渲染HUD的相机HUD Camera和画布HUD Canvas](https://i-blog.csdnimg.cn/direct/bef698481c144956bb0bce1d6490b548.png)