文章目录
- 一、SC-TIR策略(工具整合推理)
- 二、SC-TIR原理
- 三、避免过拟合
- 四、代码分析
- 1、Main函数
- 2、SC-TIR control flow
- 3、Extract answer
- 4、Execute completion
- 总结
本文较长分成两个部分分析 | ू•ૅω•́)ᵎᵎᵎ
第一部分:预备知识介绍和数据准备
第二部分:推理策略与代码分析
第二部分来了 。:.゚ヽ(。◕‿◕。)ノ゚.:。+゚, 这部分主要介绍作者的推理策略,个人觉得LLM在推理上的策略设计可以让模型有着质的改变
一、SC-TIR策略(工具整合推理)
保证模型输出和评测的稳定,作者设计自一致性工具整合推理 (SC-TIR) 来抑制高波动,流程如下图:

具体流程如下:
1)将每道题复制 N 次以生成 vLLM 的一个 batch。N 可以看成多数投票时的候选数量。
2)对这 N 个输入进行采样解码,直至生成完整的 Python 代码块。
3)执行每个 Python 代码块并将其输出串接在代码后面,包括栈回溯 (如有)。
4)重复 M 次以生成 N 个、深度为 M 的生成,允许模型使用栈回溯自纠正代码错误。如果某个样本无法生成合理的输出 (如,生成了不完整的代码块),就删除之。
5)对候选解答进行后处理,并使用多数投票来选择最终答案
二、SC-TIR原理
TIR伪代码如下:

1)首先初始化问题文本
2)循环k次进行答案生成zi
3)如果带有标记的answer在zi中,直接解析并返回答案
4)如果带有python标记的代码块不在zi中,继续下一次生成
5)如果带有python标记的代码块在zi中,使用python解释器执行,将上一次的问题ci-1, 当前生成文本zi, python执行结果ri进行拼接,执行下一次生成
从伪代码可以发现,作者没有直接计算pθ (y | x),TIR会从一个辅助潜在变量、生成的CoT计划的跟踪和Python源代码中联合得出一个答案和一系列样本。该序列记为z。因此,从TIR中得出的生成器对应于pθ (y, z | x)的样本。因此,为了有效地计算pθ (y | x),需要将生成的迹线边缘化,这可以通过以下求和来实现:

在潜在变量建模的背景下,这个方程通常被称为边际似然,当Z很大时,通常在计算上是不可行的,就像这里的情况一样。这种情况在实践中经常发生,存在各种近似策略。最值得注意的是,在边缘化LLM推理轨迹的背景下,Wang等人[2023]提出了自一致性(SC),它通过从pθ (y, z | x)中提取有限数量的n个样本y,然后应用多数投票程序,近似于最大后验(MAP)决策规则的边缘化和应用:

在SC-TIR的情况下,从TIR中生成n个样本,然后应用一个过滤器F,它去除Y支持之外的病态响应,最后应用自一致多数投票。

作者使用的 N=48,M=4 。因为增加任一参数的数值并不会提高性能,所以我们就选择了这两个最小值以保证满足时间限制。实际上,该算法通过工具整合推理增强了 CoT 的自一致性 (如下所示)。 SC-TIR 算法产生了更稳健的结果。
三、避免过拟合
为了指导模型选择,作者使用了四个内部验证集来衡量模型在不同难度的数学题上的性能。为了避免基础模型中潜在的数据污染,从 AMC12 (2022、2023) 和 AIME (2022、2023、2024) 中选择题目以创建两个内部验证数据集:
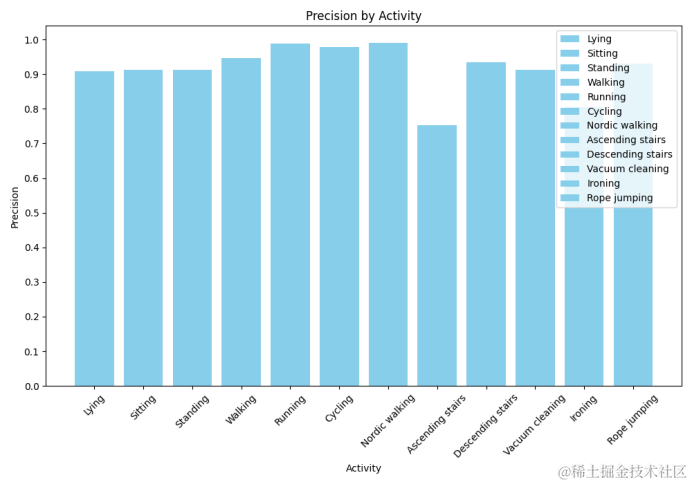
AMC (83 道题): 我们选择了 AMC12 22、AMC12 23 的所有题目,并保留了那些结果为整数的题目。最终生成的数据集包含 83 道题。该验证集旨在模拟 Kaggle 上的私有测试集,因为我们从竞赛描述中知道题目难度大于等于这个级别。我们发现我们的模型可以解答大约 60-65% 的题目。为了测量波动,每次评估时,我们使用 5-10 个不同的种子,使用我们的 SC-TIR 算法通常会看到大约 1-3% 的波动。
AIME (90 道题): 我们选择了 AIME 22、AIME 23 以及 AIME 24 的所有题目来度量我们模型解决难题的表现如何,并观测最常见的错误模式。同上,每次评估,我们使用 5-10 个种子进行以测量波动。
由于 AMC/AIME 验证集规模较小,与公开排行榜类似,这些数据集上的模型性能容易受噪声的影响。为了更好地评估模型的性能,我们还使用 MATH 测试集的子集 (含 5,000 道题) 对其进行了评估。我们仅保留答案为整数的题目,以简化多数投票并模拟奥赛评估。因此,我们又多了两个验证集: MATH 4 级 (754 道题) ,MATH 5 级 (721 道题)
通过使用这四个验证集,我们能够在不同的训练阶段选择最有潜力的模型,并缩小超参的选择范围。我们发现,对本 AIMO 赛程而言,将小型但具代表性的验证集与较大的验证集相结合是有用的,因为每个提交都受到抽样随机性的影响。
最终模型评测结果:

四、代码分析
https://www.kaggle.com/code/lewtun/numina-1st-place-solution/notebook#Python-REPL-and-code-execution-utilities
1、Main函数
基本流程如下:
1)循环每个问题并进行tokenizer化处理
2)对相同问题采样num_samples次(变成一个batch),并构建一个数据集格式用于后续处理
3)循环n次生成,对输入的文本先后进行 generate_batched(LLM生成处理),process_code(python处理)
4)在LLM生成函数中,每个问题会被赋予多个属性,对于无法获取答案的问题,其中prune属性会变为true,用于过滤
5)过滤输出,解析答案,投票获取最终答案
核心部分for test, submission in tqdm(iter_test, desc="Solving problems"): # 处理问题格式,从apply_template函数来看,并没有做什么特殊的处理problem = apply_template({"prompt": test.problem.values[0]}, tokenizer=vllm.get_tokenizer(), prompt="{}")print(f"=== INPUT FOR PROBLEM ID {test.id.values[0]} ===\n{problem}\n")# Dataset.from_list 从given list中创建一个dataset# 将一个problem循环 num_samples, 表示一个采样里面有n个相同的问题samples = Dataset.from_list([{"text": problem["text"],"gen_texts": problem["text"],"should_prune": False,"model_answers": "-1","has_code": True,}for _ in range(config.num_samples)])completed = []# 循环n次生成for step in range(config.num_generations):#samples是个dataset对象,分别执行generated_batched 和 process_code函数# process_code 函数就是SC-TIR# SC-TIR会修改sample里面的属性,判断是否should prune,has_code, model_answerssamples = samples.map(generate_batched,batch_size=128,batched=True,fn_kwargs={"vllm": vllm, "sampling_params": sampling_params},load_from_cache_file=False,)samples = samples.map(process_code,num_proc=num_procs,load_from_cache_file=False,fn_kwargs={"restart_on_fail": config.restart_on_fail, "last_step": step == (config.num_generations - 1)},)done = samples.filter(lambda x: x["should_prune"] is True, load_from_cache_file=False)if len(done):completed.append(done)# 不断迭代,直到should_prune 为True或者 完成for循环samples = samples.filter(lambda x: x["should_prune"] is False, load_from_cache_file=False) completed.append(samples)samples = concatenate_datasets(completed)candidates = samples["model_answers"]print(f"=== CANDIDATE ANSWERS ({len(candidates)}) ===\n{candidates}\n")#拿到所有正常答案filtered = filter_answers(candidates)print(f"=== FILTERED ANSWERS ({len(filtered)}) ===\n{filtered}\n")# 投票majority = get_majority_vote(filtered)print(f"=== MAJORITY ANSWER (mod 1000) ===\n{majority}\n")submission["answer"] = majorityenv.predict(submission)test["model_answer"] = majorityfinal_answers.append(test)if not config.is_submission:answers = env.df.merge(pd.concat(final_answers))answers["correct"] = answers["ground_truth"].astype(int) == answers["model_answer"].astype(int)print("Accuracy", answers["correct"].astype(int).mean())2、SC-TIR control flow
**基本流程如下:
1)首先基于正则匹配找到python代码
2)判断是否存在code block(不存在进行prune,存在执行block), 是否重启(重启保持原文本不变)
3)判断是否存在answer(存在直接解析,不存在执行python代码拿到结果和原始文本拼接,更新属性)
**
def process_code(sample, restart_on_fail, last_step, check_last_n_chars=100):gen_text = sample["gen_texts"]# 正则匹配 找到 ```python ----- ```num_python_blocks = len(re.findall(r"```python(.*?)```", gen_text, re.DOTALL))region_to_check = gen_text[-check_last_n_chars:]if num_python_blocks == 0:if restart_on_fail:print("no code has ever been generated, RESTARTING")sample["gen_texts"] = sample["text"]else:print("no code has ever been generated, STOP")sample["should_prune"] = Truesample["has_code"] = Falsereturn sample# 没有output标志 ,但是有answer标志和 boxed标志if not gen_text.endswith("```output\n") and ("answer is" in region_to_check or "\\boxed" in region_to_check):num_output_blocks = len(re.findall(r"```output(.*?)```", gen_text, re.DOTALL))if num_output_blocks == 0:print("The model hallucinated the code answer")sample["should_prune"] = Truereturn sampleif "boxed" in region_to_check:try:answer = normalize_answer(extract_boxed_answer(region_to_check))except Exception:answer = "-1"else:answer = normalize_answer(region_to_check)sample["model_answers"] = answerreturn sampleif last_step:return sample# gen_text 不存在output markif not gen_text.endswith("```output\n"):print("warning: output block not found: ", gen_text[-40:])if restart_on_fail:sample["gen_texts"] = sample["text"]else:sample["should_prune"] = Truereturn sample### gen_text 存在 output标记,且存在python block, 执行pythoncode_result, _ = postprocess_completion(gen_text, return_status=True, last_code_block=True)truncation_limit = 200if len(code_result) > truncation_limit:code_result = code_result[:truncation_limit] + " ... (output truncated)"### 这里应该就是COT技术了sample["gen_texts"] = gen_text + f"{code_result}\n```"return sample3、Extract answer
这部分代码就是提取答案,数据在定义时候会用一个\boxed{} 或者 \fbox{} ,这个函数就是在找到{}里面的内容。
def extract_boxed_answer(text):def last_boxed_only_string(text):idx = text.rfind("\\boxed")if idx < 0:idx = text.rfind("\\fbox")if idx < 0:return Nonei = idxright_brace_idx = Nonenum_left_braces_open = 0while i < len(text):if text[i] == "{":num_left_braces_open += 1if text[i] == "}":num_left_braces_open -= 1if num_left_braces_open == 0:right_brace_idx = ibreaki += 1if right_brace_idx is None:return Nonereturn text[idx : right_brace_idx + 1]4、Execute completion
def execute_completion(executor, completion, return_status, last_code_block):executions = re.findall(r"```python(.*?)```", completion, re.DOTALL)if len(executions) == 0:return completion, False if return_status else completionif last_code_block:executions = [executions[-1]]outputs = []successes = []for code in executions:success = Falsefor lib in ("subprocess", "venv"):if lib in code:output = f"{lib} is not allowed"outputs.append(output)successes.append(success)continuetry:success, output = executor(code)except TimeoutError as e:print("Code timed out")output = eif not success and not return_status:output = ""outputs.append(output)successes.append(success)output = str(outputs[-1]).strip()success = successes[-1]if return_status:return output, successreturn output总结
整个AI Mathematical Olympiad 项目大概就这样,其实真正核心的point就是数据的丰富多样性,在这个数据驱动的时代,丰富的数据比起模型设计更加重要。作者收集数据的想法和推理的策略都很值得学习。这个推理策略还是很受启发的。