本人项目地址大全:Victor94-king/NLP__ManVictor: CSDN of ManVictor
git地址:https://github.com/opendatalab/MinerU
写在前面: 笔者更新不易,希望走过路过点个关注和赞,笔芯!!!
写在前面: 笔者更新不易,希望走过路过点个关注和赞,笔芯!!!
写在前面: 笔者更新不易,希望走过路过点个关注和赞,笔芯!!!
近期RAG 应用不断涌现,它们的性能表现各具特色。尽管我们可以通过多个方面(例如查询改写、图像数据处理、分块策略、元数据管理、密集检索、稀疏检索、结果重排、排序融合、提示词优化以及上下文压缩等)逐步优化这些应用,但在选择 SOTA(State-of-the-Art)模型时,参考开源排行榜依然是必不可少的步骤。mteb/leaderboard 是一个极为有用的资源,它能帮助您了解并选择符合您需求的多语言文本生成模型。例如,在RAG系统中,无论是中文还是英文的向量化模型、重排模型或摘要模型的选择,都可以通过该榜单获得直观且量化的参考依据。
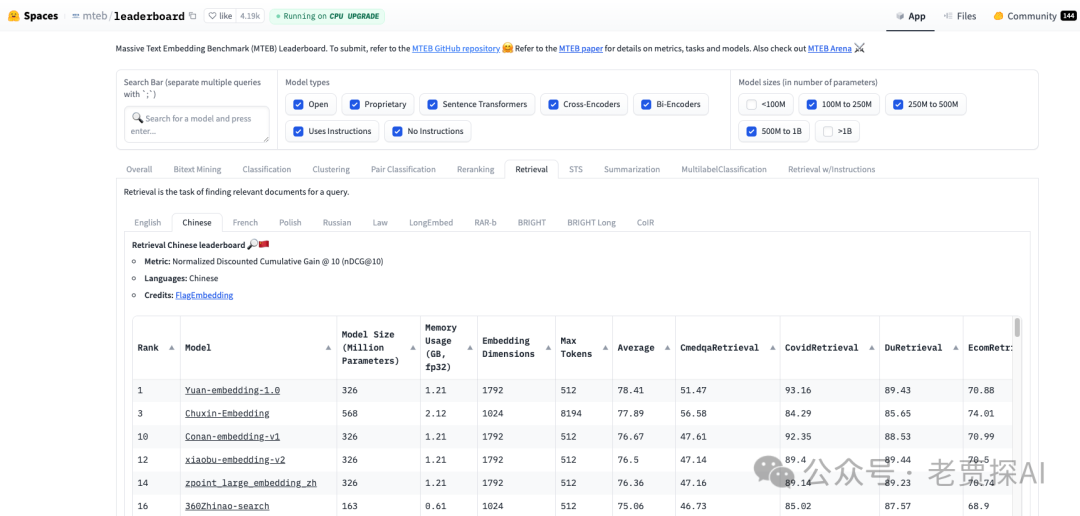
MTEB Leaderboard
MTEB(Multilingual Text-to-Text Evaluation Benchmark)是一个多语言文本嵌入的评估基准,旨在评估和比较不同多语言文本生成模型的性能。排行榜页面展示了各种模型在多个任务上的表现,这些任务可能包括但不限于翻译、摘要、问答等。
-
https://huggingface.co/spaces/mteb/leaderboard
-
C-MTEB(Chinese Massive Text Embedding Benchmark)中文语义向量评测基准
-
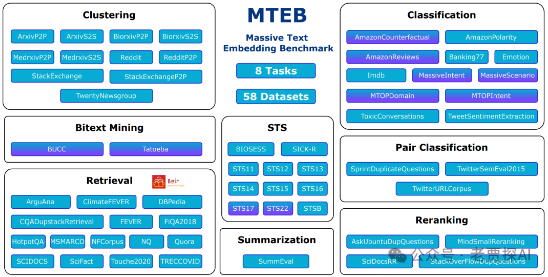
评测任务:包括涵盖112种语言的58个数据集
在 MTEB 的排行榜页面上,可以看到:
- 不同模型的名称 :列出参与评估的各种模型。
- 各项任务的得分 :每个模型在不同任务上的性能评分。
- 综合排名 :根据各项任务的得分对模型进行综合排名。
这个排行榜页面对于研究人员和开发者非常有用,因为它提供了:
- 模型性能的直观对比 :帮助选择最适合特定任务的模型。
- 最新进展的跟踪 :了解当前多语言文本生成领域的最新进展和技术趋势。
- 基准测试的参考 :为新模型的开发和评估提供基准。
如何使用
- 查看模型性能 :浏览排行榜,了解不同模型在各个任务上的表现。
- 获取模型信息 :点击模型名称或链接,可以跳转到模型的详细页面,获取更多信息和使用方法。
- 参与评估 :如果你有自己的模型,可以按照 MTEB 的评估标准提交模型进行测试,加入排行榜。
了解任务相关概念
TASK CATEGORY(任务类别)
| 枚举值 | 中文翻译 | 含义解释 |
|---|---|---|
| s2s | 句子到句子 | 任务涉及将单个句子转换或处理成另一个句子。 |
| s2p | 句子到段落 | 任务涉及将单个句子转换或处理成段落。 |
| p2p | 段落到段落 | 任务涉及将段落转换或处理成另一个段落。 |
TASK TYPE(任务类型)
| 枚举值 | 中文翻译 | 含义解释 |
|---|---|---|
| Retrieval | 检索 | 从大量数据中检索出相关信息。 |
| Reranking | 重排 | 根据某种标准重新排序数据。 |
| STS | 语义文本相似度 | 评估两个文本之间的语义相似度。 |
| Summarization | 摘要 | 生成文本的简短摘要。 |
| InstructionRetrieval | 指令检索 | 检索与特定指令相关的信息。 |
| Speed | 速度 | 评估处理或响应的速度。 |
| BitextMining | 双语文本挖掘 | 从双语文本中挖掘信息。 |
| Classification | 分类 | 将数据分配到预定义的类别中。 |
| MultilabelClassification | 多标签分类 | 为数据分配多个类别标签。 |
| Clustering | 聚类 | 将数据分组,使得同一组内的数据点相似度高。 |
| PairClassification | 配对分类 | 对成对的数据进行分类。 |
TASK SUBTYPE(任务子类型)
| 枚举值 | 中文翻译 | 含义解释 |
|---|---|---|
| Article retrieval | 文章检索 | 从大量文章中检索出与查询相关的文档。 |
| Conversational retrieval | 对话检索 | 检索与对话上下文相关的信息或回复。 |
| Dialect pairing | 方言配对 | 识别和匹配不同方言之间的对应关系。 |
| Dialog Systems | 对话系统 | 构建能够与用户进行自然对话的系统。 |
| Discourse coherence | 话语连贯性 | 评估或生成连贯、逻辑一致的长篇话语。 |
| Language identification | 语言识别 | 识别文本所使用的语言。 |
| Linguistic acceptability | 语言可接受性 | 评估文本是否符合语言学的规范。 |
| Political classification | 政治分类 | 根据政治倾向对信息进行分类。 |
| Question answering | 问答 | 回答用户提出的问题。 |
| Sentiment/Hate speech | 情感/仇恨言论 | 识别文本中的情感倾向或仇恨言论。 |
| Thematic clustering | 主题聚类 | 将文本根据主题进行分组。 |
| Scientific Reranking | 科学重排 | 对科学文献或信息进行重新排序。 |
| Claim verification | 事实核查 | 验证声明或信息的真实性。 |
| Topic classification | 主题分类 | 将文本按照主题进行分类。 |
| Code retrieval | 代码检索 | 检索与编程问题相关的代码片段。 |
| Cross-Lingual Semantic Discrimination | 跨语言语义区分 | 区分不同语言中相似词汇的语义差异。 |
| Textual Entailment | 文本蕴含 | 判断一个句子是否能够从另一个句子逻辑上推导出来。 |
| Counterfactual Detection | 反事实检测 | 识别和处理反事实或假设性陈述。 |
| Emotion classification | 情感分类 | 对文本中表达的情感进行分类。 |
| Reasoning as Retrieval | 推理检索 | 通过检索相关信息来辅助推理过程。 |
| Duplicate Detection | 重复检测 | 识别和处理重复或相似的内容。 |
C-MTEB(Chinese Massive Text Embedding Benchmark)榜单是专门用来评估中文Embedding模型的多任务混合评测榜单,包含了Classification、Clustering、Pair Classification、Reranking、Retrieval、STS六种任务类型,共35个公开数据集。
其中, Retrieval作为检索场景下最常用、最重要的测试任务 ,被广泛应用与大模型应用的落地场景,Retrieval任务包括查询语句和语料库,对于每个查询,从语料库中查询最相似的top-k个文档,使用BEIR相同的设置,nDCG@10是主要指标。
Retrieval是C-MTEB中的一个任务方向,共包含8个 中文文本数据集 ,涉及医疗、政策、电商、娱乐等各个方面。数据集主要有三部分组成:query、corpus、dev,其中query为中文问题,corpus为中文文档,包括了query的回答,该任务主要就是从海量corpus中检索出与query最为相关的内容。
Retrieval任务的8个子任务 :
- Ecom:中文电商领域检索任务;
- Medical:中文医疗领域检索任务;
- Covid:中文政策文件类检索任务;
- Video:中文娱乐视频领域检索任务;
- T2:来源于搜索引擎的段落排序中文基准测试;
- Dureader:来源于百度搜索引擎的段落检索任务;
- Mmarco:中文微软问答文摘检索测试;
- Cmedqa2:中文社区医疗问答测试





