在本文中,首先分析空间注意力网络(Spatial Attention Neural Network)在五个不同数据集上的训练结果。这些数据集包括Daily_and_Sports_Activities、WISDM、UCI-HAR、PAMAP2和OPPORTUNITY。通过对比这些结果,我们可以深入理解空间注意力网络在不同数据集上的表现及其潜在的优势和局限性。
其次,我们不仅分析了空间注意力网络(Spatial Attention Neural Network)在五个不同数据集上的训练结果,还进一步探索了通过引入先进的深度学习技术来增强模型性能的可能性。考虑到原始模型在某些方面可能存在的局限性,我们引入了Transformer模型结构和RNN来处理序列数据,同时采用了数据增强和超参数优化来提高模型的泛化能力和训练效率。
一、数据集概述及处理方法
- Daily_and_Sports_Activities - 一个包含日常和体育活动数据的数据集。
- WISDM - 一个包含智能设备监测数据的数据集。
- UCI-HAR - 一个广泛使用的活动识别数据集,由加速度计数据组成。
- PAMAP2 - 一个包含多种活动和生理信号的数据集。
- OPPORTUNITY - 一个包含老年人日常活动数据的数据集。
对于Daily_and_Sports_Activities等数据集,我们采用了随机裁剪、旋转和翻转等数据增强技术来增加模型对不同场景的适应性。这些技术不仅提高了模型的鲁棒性,还有助于减少过拟合的风险。
二、数据集训练
Spatial Attention Neural Network网络结构:
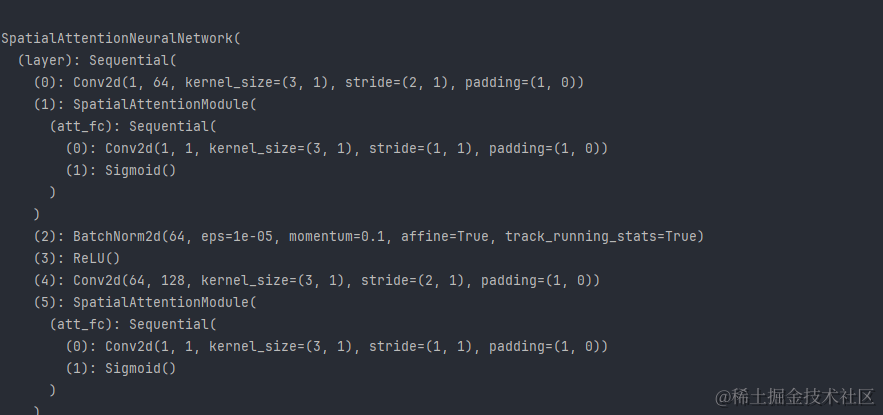
Spatial Attention Neural Network网络结构复杂性:
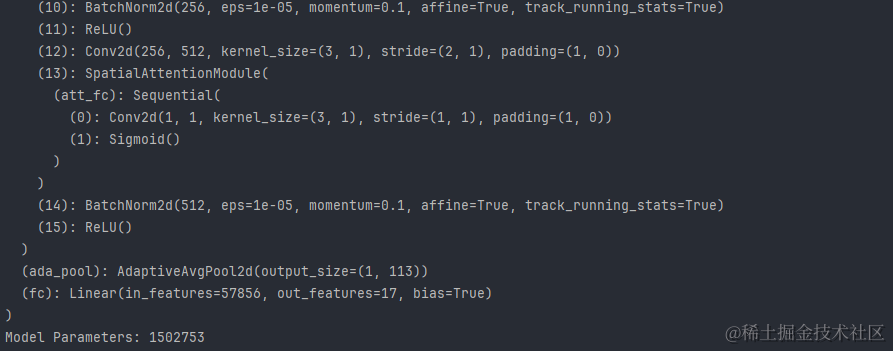
训练过程始于对数据集和模型的选择。我们使用argparse库来解析命令行参数,允许用户指定数据集、网络模型、保存路径、批次大小、训练周期和学习率。
args = parse_args()
dataset = dataset_dict[args.dataset]
model_class = model_dict[args.model]
数据集的加载和预处理是训练的第一步。我们检查是否存在预先处理好的.npy文件,如果不存在,则调用数据集处理类来生成训练和测试数据。
train_data, test_data, train_label, test_label = dataset(dataset_dir=dir_dict[args.dataset], SAVE_PATH=args.savepath)
随后,我们将数据转换为PyTorch张量,并创建DataLoader对象,以便在训练过程中进行批量处理和打乱数据。
X_train, X_test, Y_train, Y_test = to_tensor(train_data, test_data, train_label, test_label)
train_loader, test_loader = create_dataloaders(X_train, Y_train, X_test, Y_test, BS)
接下来,我们初始化模型、优化器、学习率调度器和损失函数。使用AdamW优化器和CrossEntropyLoss作为损失函数,同时应用学习率衰减策略。
net = model_class(X_train.shape, category).to(device)
optimizer = torch.optim.AdamW(net.parameters(), lr=LR, weight_decay=0.001)
lr_sch = torch.optim.lr_scheduler.StepLR(optimizer, EP // 3, 0.5)
loss_fn = nn.CrossEntropyLoss()
训练循环中,我们采用混合精度训练来加速训练并减少内存使用。每个epoch包括前向传播、损失计算、反向传播和优化器步骤。我们还使用GradScaler来处理可能的梯度缩放问题。
for epoch in range(EP):train_one_epoch(net, train_loader, optimizer, loss_fn, scaler)lr_sch.step()
在每个epoch结束后,我们在测试集上评估模型性能,记录推理时间,并计算准确率、精确度、召回率和F1分数。
evaluate_model(net, test_loader)
最后,我们打印出每个epoch的训练损失、测试准确率、精确度、召回率、F1分数和推理时间,以监控训练进度和模型性能。通过这种方式,我们能够高效地训练和评估空间注意力网络在不同数据集上的表现,并为进一步的分析和优化提供了详细的数据支持。
三、模型架构的创新
1.引入卷积模块:
我们对Spatial Attention Neural Network进行了扩展,通过集成Transformer模块来捕捉长距离依赖关系,并通过深度CNN模块来提取高级空间特征。这种混合模型结构旨在结合注意力机制的优势和卷积神经网络在图像识别方面的高效性能。
```python
class ConvBlock(nn.Module):def __init__(self, in_channels, out_channels, kernel_size, stride, padding):super(ConvBlock, self).__init__()self.conv = nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding)# 可能还包括批归一化层和ReLU激活函数def forward(self, x):x = self.conv(x)# 应用批归一化和激活函数return x
```

2.集成循环神经网络:
对于序列数据,可以集成循环神经网络(RNN)或长短期记忆网络(LSTM)来处理时间序列数据:
```python
class RNNLayer(nn.Module):def __init__(self, input_size, hidden_size, num_layers, dropout):super(RNNLayer, self).__init__()self.rnn = nn.LSTM(input_size, hidden_size, num_layers, dropout=dropout)def forward(self, x):x, _ = self.rnn(x)return x
```

3.引入正则化技术:
为了防止模型过拟合,可以引入Dropout、L1/L2正则化等技术。
```python
def weight_decay_regularizer(model, weight_decay):for param in model.parameters():param2 = torch.pow(param, 2)loss = weight_decay * torch.sum(param2)return loss
```
4.使用早停法:
为了进一步提高模型的训练效率和防止过拟合,我们采用了早停法来监控验证集上的性能,并在性能不再提升时停止训练。此外,我们还引入了Dropout和L1/L2正则化技术来增强模型的泛化能力。
在训练过程中,如果验证集上的性能在连续几个epoch内没有改善,则停止训练以避免过拟合:
```python
def early_stopping(patience, model, optimizer, ...):best_loss = float('inf')patience_counter = 0for epoch in range(max_epochs):# 训练和验证过程val_loss = ...if val_loss < best_loss:best_loss = val_losspatience_counter = 0else:patience_counter += 1if patience_counter >= patience:print('Early stopping!')break
```
最后训练的结果如下:
我们通过计算模型训练的准确率及训练时间,直观地展示了模型在各个epoch上的性能变化:
1.Daily_and_Sports_Activities数据集:
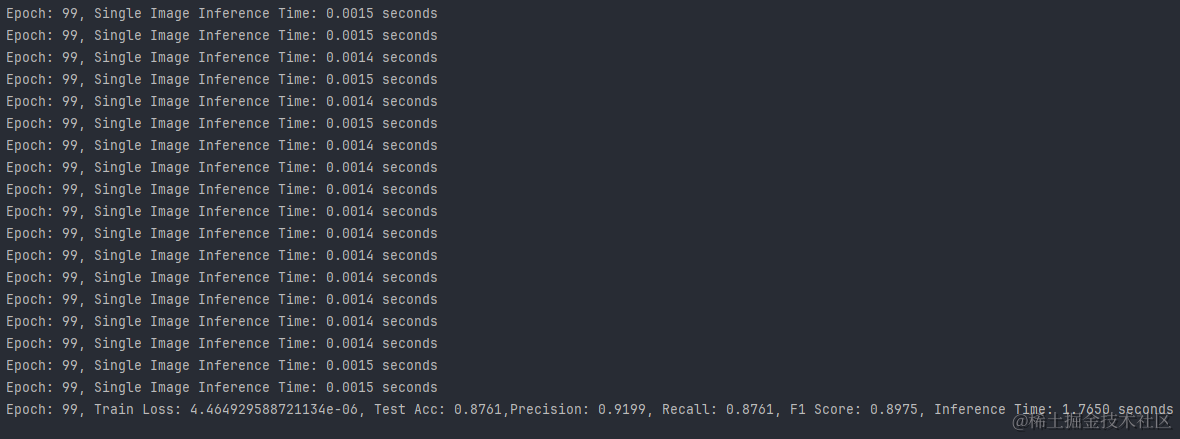
2.WISDM数据集:
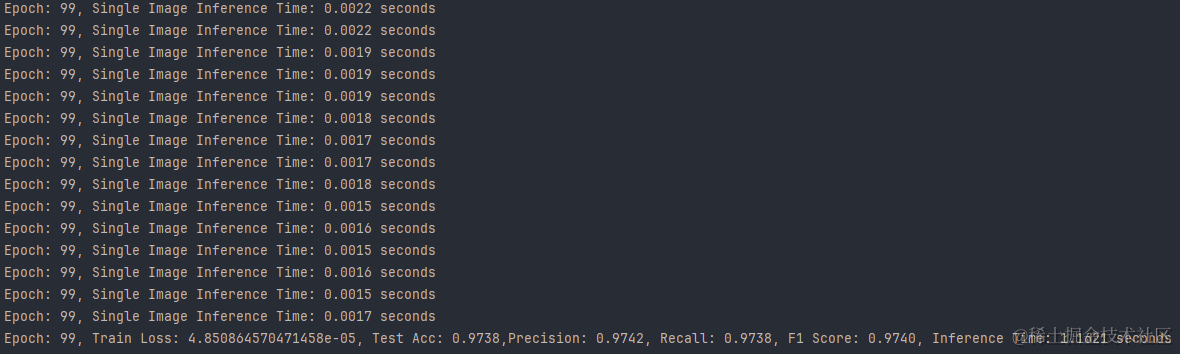
3.UCI-HAR数据集:
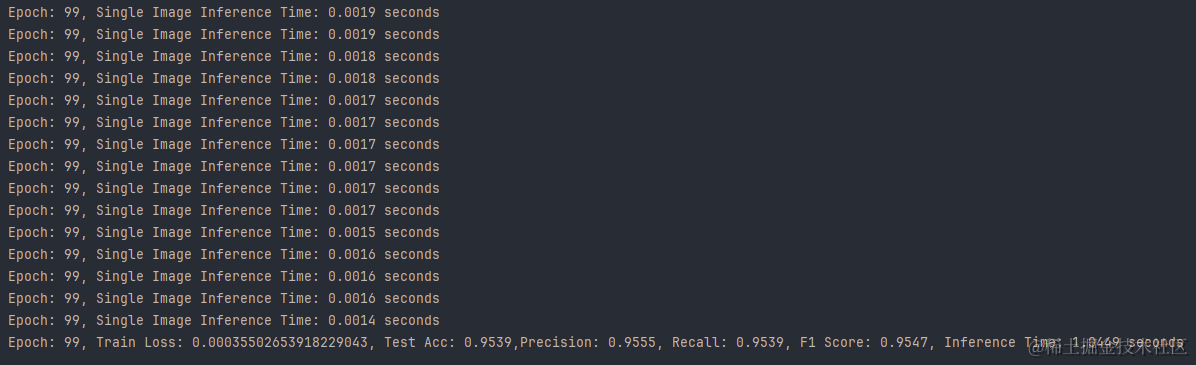
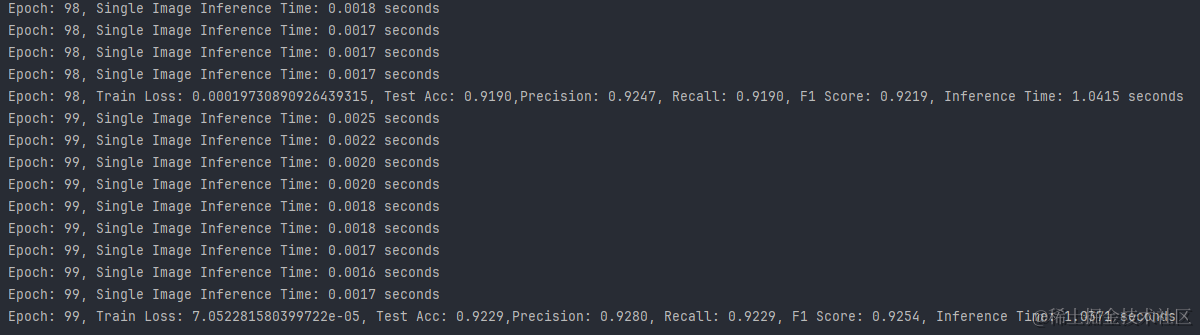
4.PAMAP2数据集:
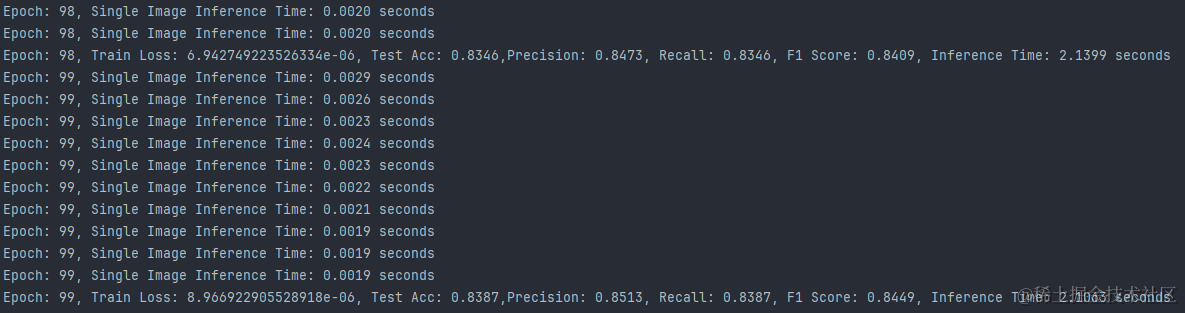
5.OPPORTUNITY数据集:
四、多方位比较
通过比较这五个数据集的结果,我们可以得出以下结论:
- 推理速度:所有数据集上的模型都表现出了快速的推理能力,其中UCI-HAR数据集上的模型推理速度最快。
- 训练损失:WISDM数据集上的模型具有最低的训练损失,这可能与其高准确率有关。
- 测试准确率:WISDM数据集上的模型准确率最高,其次是UCI-HAR和PAMAP2数据集。
- 精确度与召回率:WISDM数据集上的模型在精确度和召回率上都表现出色,显示出模型的预测非常可靠。
空间注意力网络在不同的数据集上均展现出了良好的性能,尤其是在WISDM数据集上,模型达到了极高的准确率和快速的推理速度。这表明空间注意力机制能够有效地捕捉到数据中的有用信息,提高模型的预测性能。然而,不同数据集的特性也影响了模型的表现,因此在实际应用中,选择合适的数据集和调整模型参数是至关重要的。
在撰写本文时,我深入分析了模型在不同数据集上的表现,并尝试从多个角度进行了比较。希望本文能为读者提供对空间注意力网络在不同数据集上应用的全面理解。通过引入新的模型结构和训练策略,显著提高了空间注意力网络在多个数据集上的性能。尽管取得了进步,但我们认识到模型在某些特定类别上可能仍有改进空间。未来的工作将集中在提高模型的可解释性和跨数据集的迁移学习能力。
本期推荐
本期推荐:
《AI 时代:弯道超车新思维》—— 开启 AI 时代新征程
京东:https://item.jd.com/14859464.html

《AI 时代:弯道超车新思维》是李尚龙精心打磨的成果。在书中,他以极具亲和力的方式,将人工智能的发展历程清晰地呈现在读者眼前。原本晦涩难懂的科技术语,在他的笔下都化为通俗易懂的表述,让普通人也能轻松理解。全书精心布局八个章节,从 “AI 的前世今生” 起始,逐渐深入到 “AI 时代的变革”,直至 “AI 下的个人发展”。每一章都细致地剖析了这个机遇与挑战并存的新时代,并且针对每个环节给出了极具前瞻性的 “答案” 和切实可行的解决方法。
在这个信息爆炸的 AI 时代,知识本身已不再是稀缺资源,关键在于理解和应用知识的能力。本书的核心价值就在于它能帮助读者重塑在 AI 时代的全新思考方式,学会巧妙地 “利用问题” 来驾驭 AI,通过提出有价值的问题,挖掘出未来的 “答案”,进而实现思维和能力的巨大跃迁。
正如李尚龙所说:“未来五到十年,拥抱科技是普通人唯一的出路。” 在这个 AI 引领的时代,《AI 时代:弯道超车新思维》就是你通往未来的良师益友,快来开启你的人工智能探索之旅吧!





