241124_文本解码原理
一个文本序列的概率分布可以分解为每个词基于其上文的条件概率的乘积。

Greedy search
就是每步都选择概率最大的,不会去考虑全局
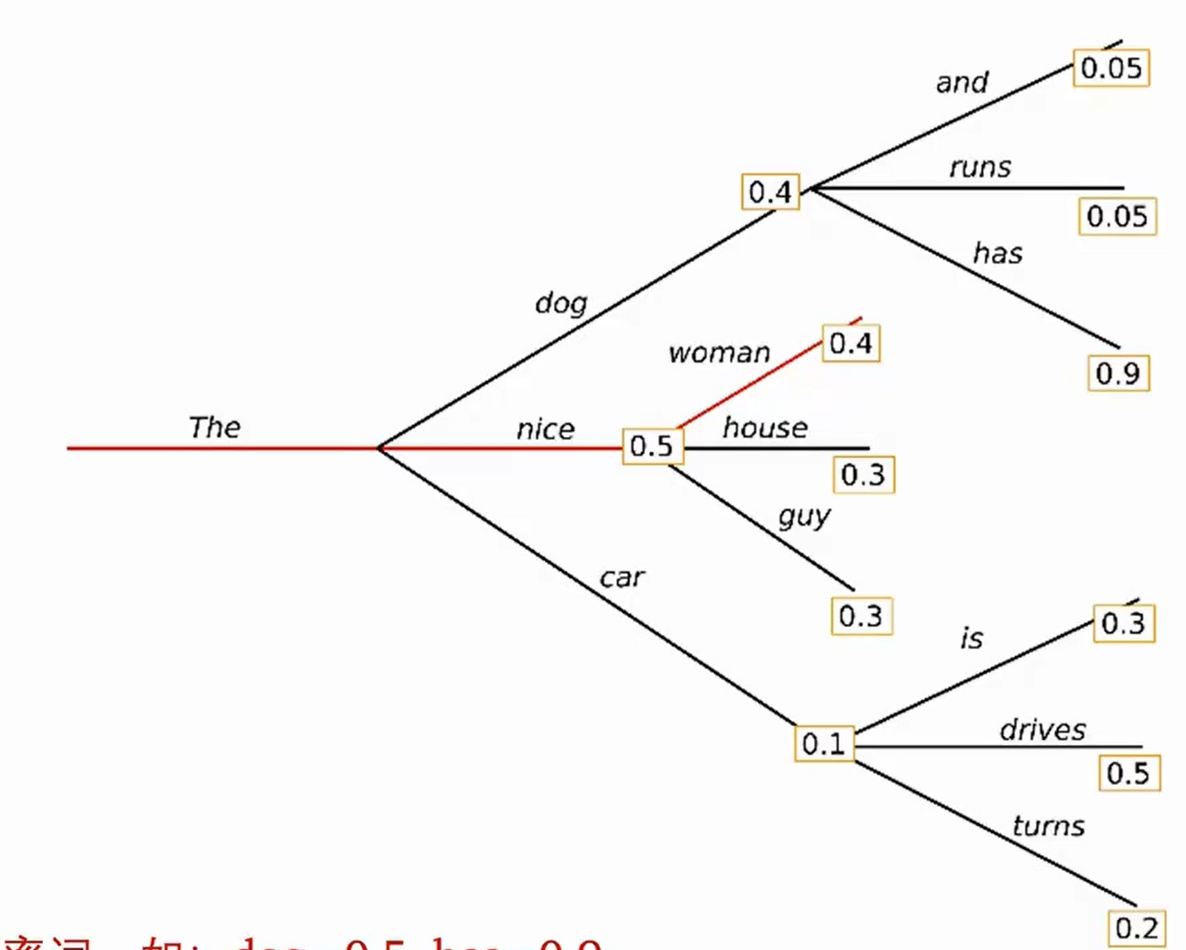
按照贪心搜索输出the nice woman 的概率就是0.5*0.4=0.2
这种方法简单,但也存在问题,比如错过了隐藏在较低概率词后面的高概率词,如has=0.9
Beam search
(图还用上面的)
比如设定num_beams=3,就是到每个节点保留概率最高的三个分支,然后进入分支,遇到分岔再次保留三个分支。最后计算到保留的所有概率,进行比较
使用这种方法就可以保留到上图的the dog has的语句。
一定程度上缓解了Gready search的弊端,但是依旧不完备。如果遇到极低概率后隐藏极高概率的分支,就保留不到。
实质上就是个剪枝。
缺点:无法解决重复问题(每次遇到相同的分支都会选择同样的结果,死循环无限生成同样的)。开放域生成效果差()。
解决重复问题的方法:
n-gram惩罚:将出现过的候选词的强行概率设置为0,过于简单粗暴,不合理。实际文本生成有重复出现的场景。
优化一点的方法就是不那么极端直接赋0,而是乘以一个小于1的系数,缩小其概率。
Sample
根据当前概率分布随机选择输出词。就是不看概率,直接随机选。生成文本的多样性确实高了,但是会产生“我认为意大利面就应该拌42号混凝土”的问题。
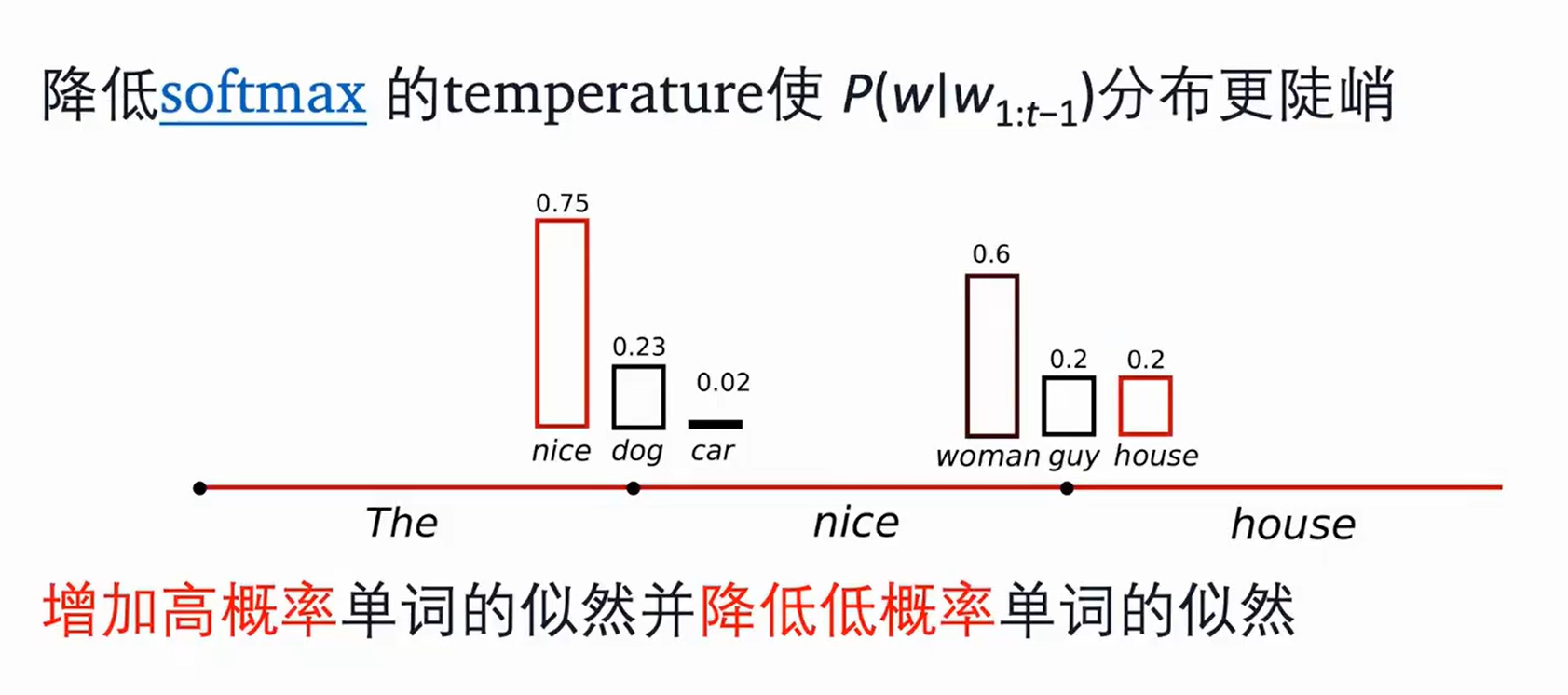
Temperature
有一定的随机性但不完全随机
TopK sample
选出概率最大的K个词,重新归一化,最后在归一化后的K个词中采样
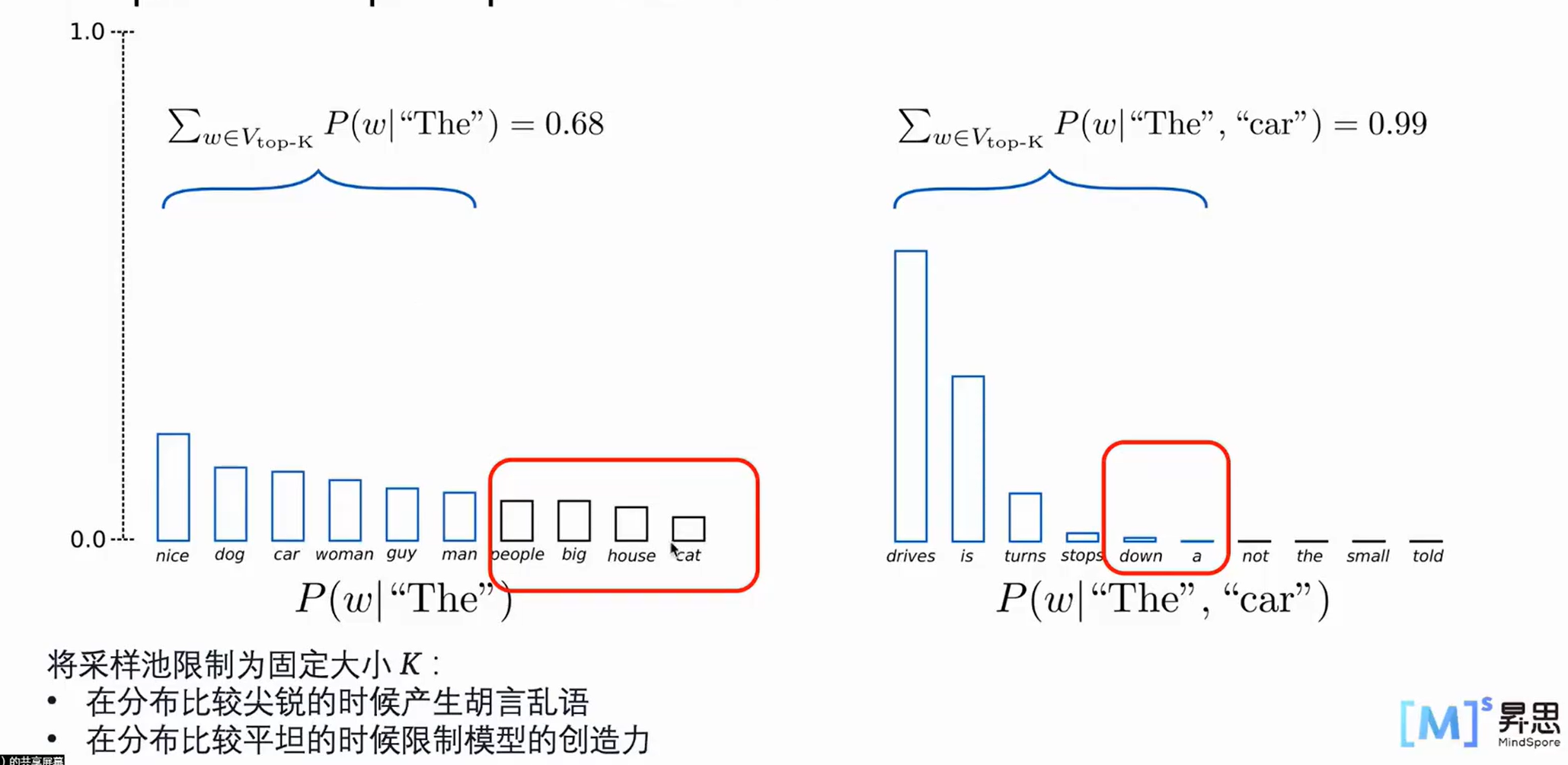
尖锐指右侧,a和down的概率已经比较低了,但是还是在下限内,所以也会取到,造成胡言乱语
平坦指左侧,一刀切会切掉低一点点的那些单词
Top-P sample
在累积概率超过概率p的最小单词集中进行采样,重新归一化
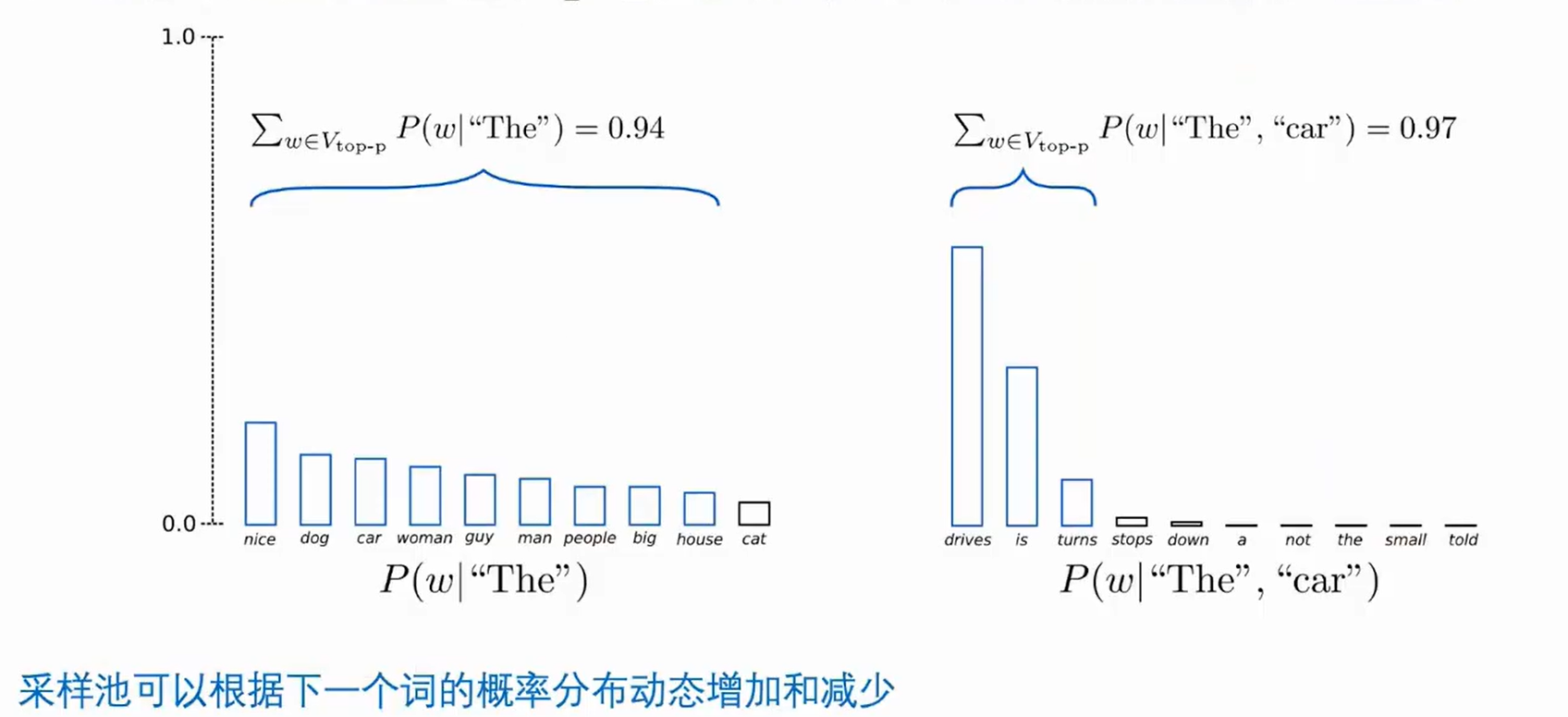
使用比例选择有效解决了上面采样方法的问题,在比较平坦的时候会尽可能取到更多的单词,在尖锐的时候取到最大的几个词。
Constrastive Search

这个没太听明白,先记录
打卡截图: