前言:Apache Kafka是一个分布式流处理平台,由LinkedIn开发并捐赠给Apache软件基金会。它主要用于构建实时数据流管道和流应用。Kafka具有高吞吐量、可扩展性和容错性的特点,适用于处理大量数据。
以下是Kafka的一些核心概念和特性:
-
主题(Topic):Kafka中消息的分类,生产者(Producer)将消息发送到特定的主题,消费者(Consumer)从主题中读取消息。
-
分区(Partition):为了提高并行性和吞吐量,每个主题可以被分割成多个分区。分区可以分布在集群中的不同服务器上。
-
生产者(Producer):向Kafka集群发送消息的客户端。
-
消费者(Consumer):从Kafka集群读取消息的客户端。消费者通常以消费者组(Consumer Group)的形式存在,每个消费者组中的消费者可以独立地读取消息。
-
消费者组(Consumer Group):是一组共享相同主题订阅的消费者。消费者组允许多个消费者实例共同处理主题中的消息。
-
Broker:Kafka集群中的一个节点,负责存储数据并提供数据服务。
-
ZooKeeper:Kafka使用ZooKeeper来维护集群元数据和协调集群操作。
-
消息(Message):Kafka中的基本数据单元,由键(Key)、值(Value)、时间戳等组成。
-
偏移量(Offset):每个分区中消息的索引,消费者通过偏移量来追踪其在分区中的位置。
-
副本(Replica):为了提高数据的可靠性和可用性,Kafka中的每个分区都有多个副本。其中一个副本是领导者(Leader),其他副本是追随者(Follower)。
-
领导者选举(Leader Election):当分区的领导者不可用时,追随者之一会被选为新的领导者。
-
高可用性(High Availability, HA):通过副本和领导者选举机制,Kafka能够保证服务的高可用性。
-
持久性(Durability):Kafka提供了消息持久化机制,确保消息不会因为系统故障而丢失。
-
可伸缩性(Scalability):Kafka可以通过增加更多的Broker来水平扩展,以处理更多的数据。
-
容错性(Fault Tolerance):Kafka通过副本机制来容忍节点故障。
Kafka的应用场景包括:
- 日志聚合:收集和集中分布式系统中的日志数据。
- 实时数据分析:流式处理和分析实时数据。
- 事件源(Event Sourcing):使用事件来记录系统中发生的状态变化。
- 消息队列:作为消息队列系统,用于任务分发和解耦服务。
- 流处理:构建复杂的流处理应用,如实时监控、报警系统等。
Kafka通常与其他技术(如Apache Flink、Apache Storm、Apache Samza等)结合使用,以构建完整的流处理解决方案。
安装kafka集群:
第一步:创建文件夹路径
命令:mkdir -p /var/kafka-logs /data/zk
命令:mkdir -p /usr/local/kafka
第二步:上传压缩包到 /usr/local/kafka
解压,进入解压后的目录/kafka-3.0.0/kafka_2.12-3.0.0
tar -zxvf kafka_2.12-3.0.0.tgz
cd kafka_2.12-3.0.0
第三步:修改配置文件
修改/usr/local/kafka/kafka_2.12-3.0.0/config/server.properties
vim server.properties修改以下内容:
broker.id=0 #保证每个broker唯一,第一台可以不修改默认为0,后面两台需要修改,如改为1和2
num.partitions=3 #分区数量一般与broker保持一致
listeners=PLAINTEXT://10.0.0.8:9092 #修改为本机ip
zookeeper.connect=10.0.0.8:2181,10.0.0.9:2181,10.0.0.10:2181 #配置三台服务zookeeper连接地址
host.name=10.0.0.8 #新增host.name值,分别设为不同的值(3台机器根据自己的ip设置)
log.dirs=/var/kafka-logs/ #修改log.dirs目录
修改/kafka-3.0.0/kafka_2.12-3.0.0/config/zookeeper.properties
dataDir=/data/zk #修改为自定义的目录
maxClientCnxns=0 #注释掉
#设置连接参数,添加如下配置
tickTime=2000
initLimit=10
syncLimit=5
#设置broker Id的服务地址
server.0=10.0.0.8:2888:3888
server.1=10.0.0.9:2888:3888
server.2=10.0.0.10:2888:3888
而消费者配置consumer.properites和生产者配置producer.properties根据具体业务来进行调配
第四步:
三台服务器分别执行如下命令:myid的值取决于broker.id
echo 0 > /data/zk/myid
echo 1 > /data/zk/myid
echo 2 > /data/zk/myid
第五步:配置hosts文件
查看主机名命令:hostname
10.0.0.8 ecs-ubiinf6as0wpbx
10.0.0.9 ecs-8k9rxzfxvsuyp2
10.0.010 ecs-bodhwf981mt5r9
命令:vim /etc/hosts
注释掉本机的,加入以上三条信息

第六步:启动
kafka启动时先启动zookeeper,再启动kafka;关闭时相反,先关闭kafka,再关闭zookeeper
启动zookeeper:
./zookeeper-server-start.sh /usr/local/kafka/kafka_2.12-3.0.0/config/zookeeper.properties &
启动kafka:
./kafka-server-start.sh /usr/local/kafka/kafka_2.12-3.0.0/config/server.properties &
查看日志:
tail -f /usr/local/kafka/kafka_2.12-3.0.0/logs/server.log
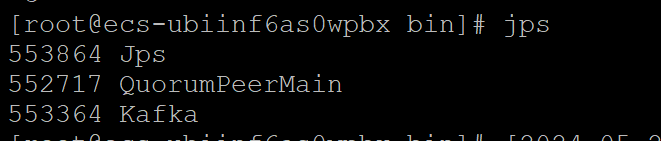
Kafka集群配置成功,且无集群节点连接异常报错
第七步:放行端口
如集群配置完成后开启防火墙报节点无法连接,需做放行端口配置:
放行端口:
firewall-cmd --zone=public --add-port=2888/tcp --permanent 放行2888端口
firewall-cmd --zone=public --add-port=3888/tcp --permanent 放行3888端口
firewall-cmd --zone=public --add-port=9092/tcp --permanent 放行9092端口firewall-cmd --reload #重新载入 返回 success 代表成功firewall-cmd --zone=public --query-port=2888/tcp 查看 返回 yes 代表开启成功
firewall-cmd --zone=public --query-port=3888/tcp 查看 返回 yes 代表开启成功
firewall-cmd --zone=public --query-port=9092/tcp 查看 返回 yes 代表开启成功