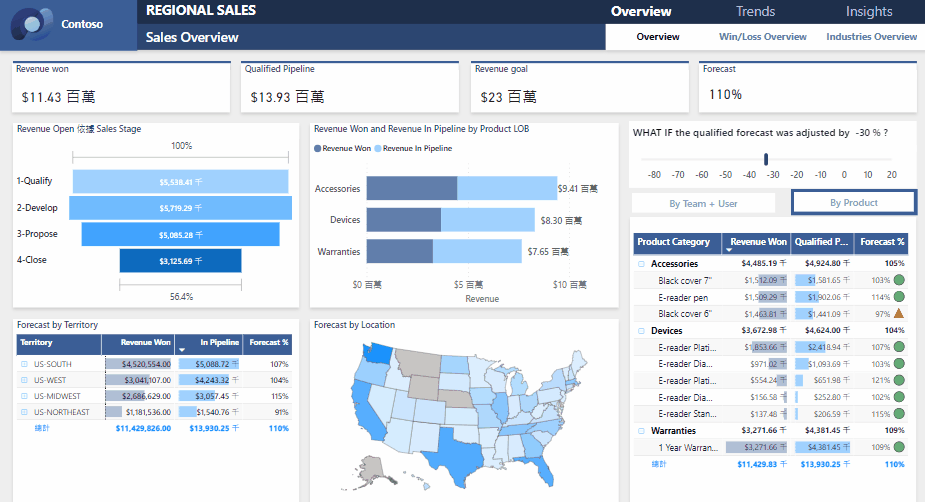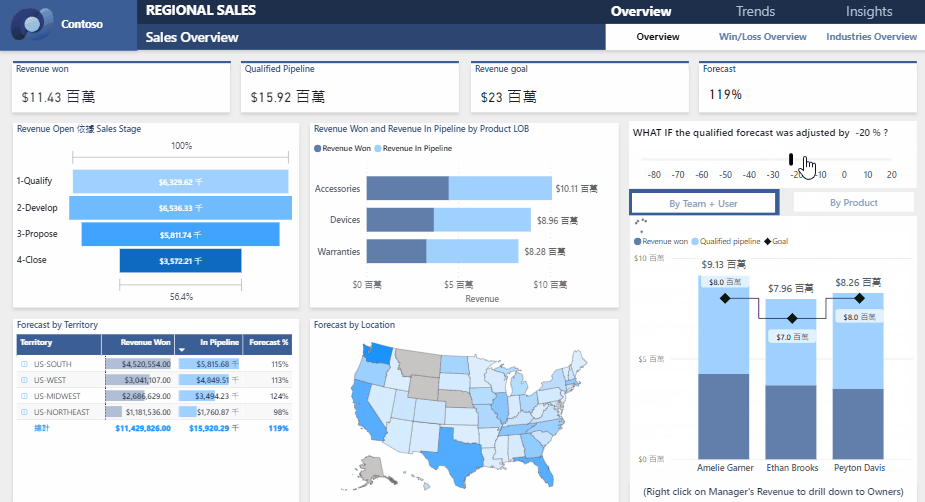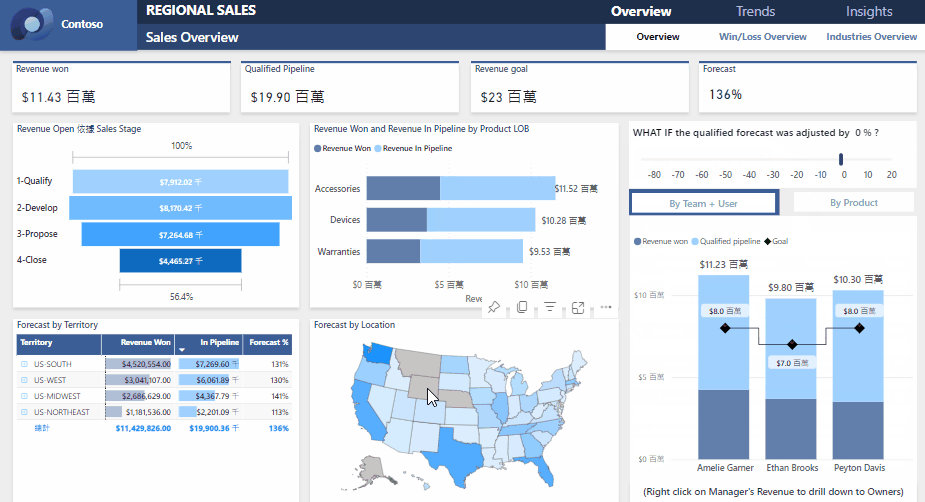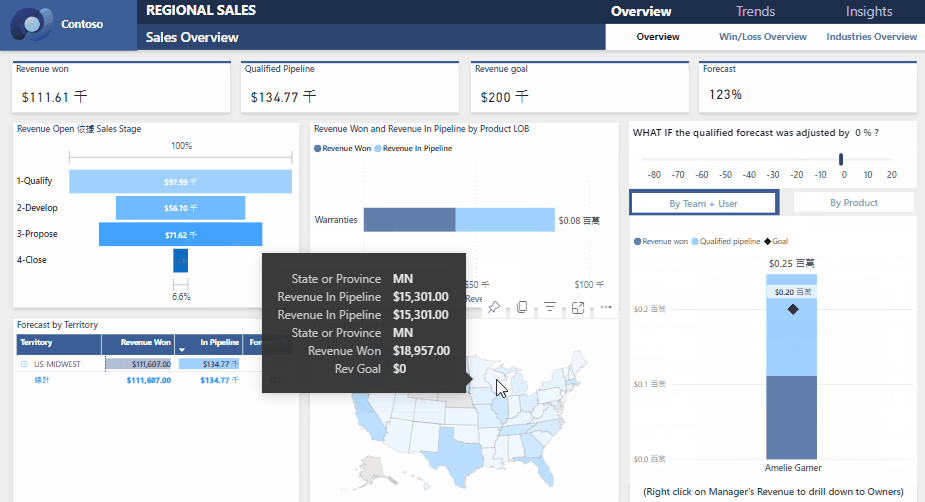
梯度提升树(Gradient Boosting Decision Trees,GBDT)是一种强大的机器学习方法,广泛用于回归和分类任务。它通过构建一系列决策树来优化模型的预测能力,基于梯度提升框架,使得每一棵树都试图纠正前一棵树的错误。
注:文章中的 x = (f1,f2,...,fn)是一个特征向量,fn 为 x 的一个特征。
GBDT基本原理
GBDT 的基本思想是:GBDT通过一棵棵新增的树来修正前面模型的误差。在每一轮迭代中,GBDT会构建一棵新树,这棵树的作用是拟合当前模型在训练数据上的残差(即预测值和真实值之间的误差),逐步改进模型的预测能力。它是一个集成学习方法,采用了“加法模型”和“梯度下降”思想。
1、加法模型
GBDT 是一种加法模型,即每一轮迭代都会新增一棵决策树,通过将新的树加到现有模型 F(x)中来改善预测。假设我们要构建的模型为 F(x),每一轮迭代的目标是通过拟合残差来更新模型。
2、构建初始模型
-
对于分类问题(以二分类问题为例),初始模型为对数几率:
其中p为样本中类别1的概率。
-
对于回归问题,初始模型一般为训练集目标值的均值:
3、GBDT迭代过程
3.1 假设模型的预测值(即所求模型,待优化)为:

上述说的步长γM是一个学习率,控制树的贡献大小,通常通过交叉验证等方法选择合适的值。
3.3 目标损失函数L
-
对于回归任务,常用的损失函数是均方误差(MSE):

-
对于二分类任务,常用的损失函数是对数损失函数:

-
对于多分类任务,常用的损失函数是交叉熵损失函数:

3.4 计算梯度
-
计算负梯度:在第 M 轮迭代时,计算损失函数L相对于
预测值的负梯度(即求损失函数在xi处的一阶导数值,再取负)。
(以MSE损失函数为例)对于样本i,负梯度计算公式为:

3.5 训练新树拟合误差(负梯度)
每一轮迭代的目标是训练一棵决策树 ,使这棵决策树的预测值尽可能接近模型
的误差(或者叫残差)。
加上这一近似误差,就修正了部分
预测的误差,得到了预测误差更小的模型
(对照3.1的公式)。这是一个重复M次迭代的过程。
-
上面的论述中,为什么要
-
讲一下梯度下降思想:沿负梯度方向修正误差
GBDT优化的核心思想之一是梯度下降。在每一轮迭代中,我们希望模型能沿着损失函数的负梯度方向进行优化。梯度等同于模型的误差或残差。这么理解,损失函数的损失方向是正方向,那么其反方向就是修正损失的方向,再俗一点讲,修正误差就是误差(梯度)的相反数,修正误差就是损失函数的负梯度。因此, 加上的误差,实际上应该是加上误差的相反数(即负梯度或修正误差),要用加号。
-
那怎么训练这颗决策树呢?
1、首先,通过计算负梯度,我们得到了每个样本 i 的修正误差
2、接着,修正误差与特征向量x结合,我们得到一个新数据集(x1,g1),... ,(xn,gn),
其中,每个数据集的xi是特征向量,修正误差gi为目标变量
3、根据这个新数据集训练决策树 ,使得对于一个未知的x,我们能预测出修正误差
(决策树的具体训练过程参考另一篇文章:A)
3. 5 更新模型预测值
训练一棵决策树 后,我们再结合学习率,更新模型

3.6 迭代M次,不断优化模型(M是一个超参数,通常由交叉验证等方法来选择合适的值)
4、最终模型
经过 M 次迭代,最终模型的预测结果是所有决策树的加权和,即:

步骤总结
-
初始模型:建立一个初始预测模型。
-
残差计算:在每一轮迭代中,计算上一个模型的预测误差(纠正误差/残差)。
-
拟合残差:通过训练一个新的决策树(弱学习器)来拟合这些残差。新模型的目的是减少之前模型在数据上的误差。
-
更新模型:将新训练的决策树加入到当前模型中,通常通过一个学习率参数来调节新模型的贡献。这一步就是提升的过程,即逐步优化模型以减小误差。
-
重复迭代:通过多个迭代,不断引入新的决策树,每次迭代都尽量减少当前模型的损失,逐步逼近最优解。
GBDT的优点
-
适合处理非线性数据:GBDT 通过构建多棵决策树的方式,能够灵活地拟合数据中的非线性特征。
-
对数据预处理要求较低:GBDT 不需要对数据进行严格的标准化或正则化处理,能够自动处理不同的特征尺度。此外,它对缺失值也比较鲁棒。
-
处理多种数据类型:GBDT 适合处理类别特征和数值特征,且对类别特征不需要特别的编码(如独热编码),直接输入即可。(特征编码可以参考文章:B)
-
鲁棒性高,抗过拟合能力强:GBDT在处理异常值和噪声数据时表现较好。由于它采用集成学习的方式,并通过提升(boosting)算法逐步修正错误,模型对数据中的噪声不敏感,具有较好的鲁棒性。。
-
灵活性和扩展性:GBDT不仅适用于回归和分类任务,还可以扩展到排序、异常检测等任务。GBDT可以根据任务的不同,选择不同的损失函数,比如平方损失、对数损失等,从而适应多种不同类型的问题。
-
高准确性和强泛化能力:GBDT结合了多个弱学习器的预测结果,能够有效地降低误差,具有较强的泛化能力。它在许多实际应用中表现出色,尤其是在复杂的非线性问题中能够获得高准确度。
-
强大的特征选择能力:由于GBDT也基于决策树,构建过程中会不断选择分裂特征来最大化信息增益,因此它天然具备特征选择的功能。GBDT可以对特征的重要性进行排序,从而帮助我们识别哪些特征对预测结果最为重要。
GBDT的缺点
-
计算效率较低,训练速度慢:GBDT模型的训练过程是串行的,每棵树都依赖于前一棵树的结果,因此无法并行化。随着树的数量增加,训练时间会显著增长,特别是在大数据集上的表现不够理想。此外,由于每棵树的构建都需要多次计算分裂点,所以计算成本较高。
-
容易过拟合:由于GBDT会逐步叠加新的树来减少训练误差,在数据量较小或特征过多的情况下,模型可能会学习到噪声数据,从而导致过拟合。尽管可以通过设置学习率、树的最大深度、树的数量等参数来进行控制,但仍然难以完全避免过拟合。
-
对参数敏感,调参复杂:GBDT有多个超参数需要调节,比如学习率、树的数量、最大深度、叶子节点数等。不同数据集可能需要不同的参数组合,参数调优过程较为复杂且耗时,特别是在大数据集上,调参成本会进一步增加。
-
对缺失值敏感:传统GBDT无法直接处理缺失值。与XGBoost等改进版本不同,GBDT通常要求在数据预处理阶段处理缺失值,比如填补或删除缺失值,否则可能会影响模型的性能。
-
内存占用较大:随着树的数量增加,GBDT的内存占用会迅速增大。尤其在大规模数据上,GBDT可能占用大量的内存资源,对于计算资源要求较高。
-
不适合高维稀疏数据:GBDT在处理高维稀疏数据(如文本数据或其他表示方式稀疏的特征)时表现较差。由于决策树的分裂过程依赖于特征的具体数值,GBDT在这类数据上效率较低。相比之下,线性模型或者神经网络在稀疏数据上的表现可能更好。
随机森林 vs GBDT

# 文章内容来源于各渠道整理。若对大噶有帮助的话,希望点个赞支持一下叭!
# 文章如有错误,欢迎大噶指正!