概述
由于情绪在人机交互中扮演着重要角色,因此情绪识别备受研究人员关注。目前的情感识别研究主要集中在两个方面:一是识别刺激物引起的情感,并预测观众观看这些刺激物后的感受。另一个方面是分析图像和视频中的人类情绪。在本文中,这些任务统称为广义情感识别(GER)。
情绪可以通过文字、音频和视频等不同方式传达。其中,视觉信息(如色彩、亮度、面部表情、人类行为)包含丰富的情绪相关内容,在广义情绪识别任务中发挥着重要作用。为了提高视觉理解能力,研究人员提出了各种算法,并取得了显著进展。随着深度学习的发展,目前泛化情感识别的研究已从人工特征设计转向深度神经网络。
最近,GPT-4V 在各种任务中表现出了令人印象深刻的视觉理解能力。这就提出了一个问题:GPT-4V能在多大程度上解决泛化情绪识别问题?
2023 年 9 月,GPT-4V 被集成到 ChatGPT 中,并发布了调查其可视化功能的用户报告。然而,这些报告中每个任务的样本数量通常有限,只能提供有关 GPT-4V 的定性见解。openAI 于 2023 年 11 月发布了 API,最初仅限于每天 100 个请求。因此,GPT-4V 仍然难以与基准数据集的最先进系统进行对比评估。最近,OpenAI 增加了每日请求限制,以便进行更全面的评估。
本文提供了 GPT-4V 在通用情感识别任务中的定量评估结果,包括视觉情感分析、微表情识别、面部情感识别、动态面部情感识别和多模态情感识别。
下图显示了 GPT-4V 的总体结果,其性能优于随机猜测,但与监督系统相比仍有差距。为了揭示其中的原因,我们对 GPT-4V 的多方面性能进行了综合分析,包括其多模态融合能力、时间建模能力、色彩空间鲁棒性和预测一致性。
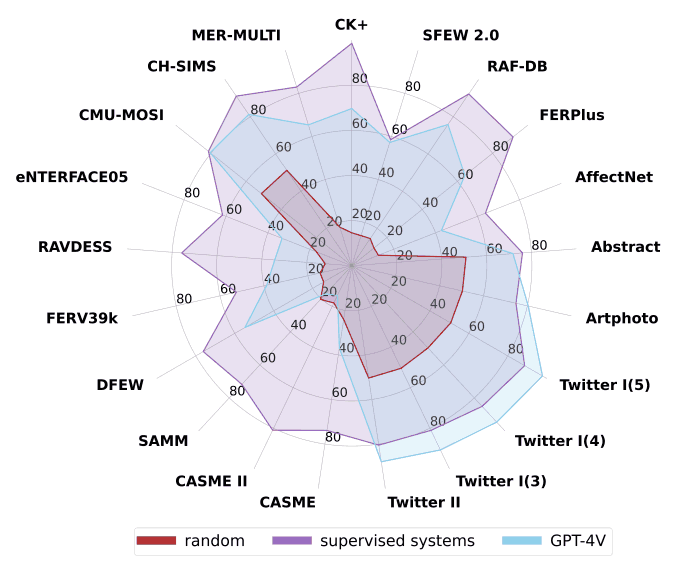
本文旨在为后续研究人员提供建议,并就 GPT-4V 能够有效解决哪些任务以及哪些任务需要进一步探索提出问题。
实验概述
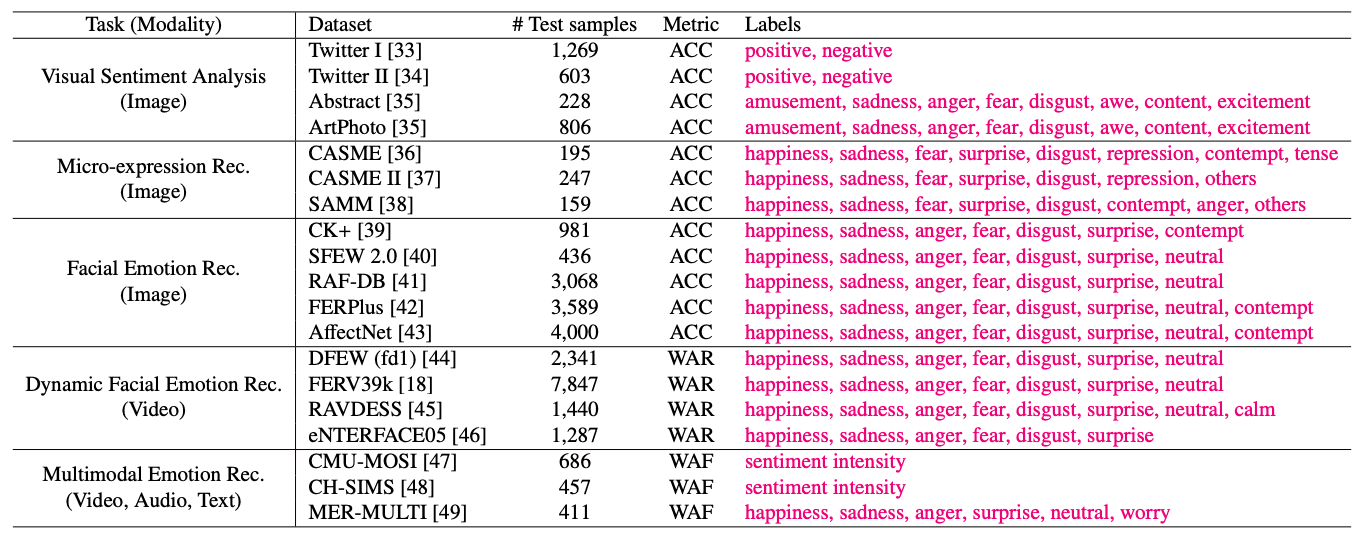
本文对 19 个数据集的五项任务进行了综合评估。下表提供了每个数据集的统计数据。
下图显示了每个数据集的样本。其中既有在自然环境中收集的数据集(如 AffectNet),也有在受控实验室环境中收集的数据集(如 CASME 和 CK+);既有使用灰度图像的数据集(CK+),也有使用 RGB 图像的数据集(CASME 和 AffectNet)。AffectNet)以及其他各种数据集。

在五项任务中,第一项任务 "视觉情绪分析 "旨在识别图像引发的情绪。使用的四个数据集分别是 Twitter I、Twitter II、ArtPhoto 和 Abstract。Twitter I 和 Twitter II 收集自社交网站,Twitter I 的原始数据来自 Amazon Mechanical Turk 工作者;ArtPhoto 包含来自照片分享网站的艺术照片;Abstract 包含由同行评价的抽象画。这些数据集被重新分类为积极和消极两类,并报告了消极/积极分类任务的结果。
面部情绪识别使用了五个基准数据集:CK+、FERPlus、SFEW 2.0、RAF-DB 和 AffectNet;CK+ 和 FERPlus 包含灰度图像,SFEW 2.0、RAF-DB 和 AffectNet 包含 RGB 图像。CK+ 和 FERPlus 包含灰度图像。具体来说,CK+ 包含来自 123 个受试者的 593 个视频序列,每个序列的最后三帧被提取出来以构建数据集。
FERPlus 是 FER2013 的扩展,其中每个样本都由 10 位注释者重新标注;SFEW 2.0 从电影片段中提取关键帧,包括各种头部姿势、遮挡和照明;RAF-DB 包括数千个基本和复杂的面部表情样本。而 AffectNet 有 8 个标签,每个标签包含 500 个样本�
微表情识别也旨在识别人脸的细微变化。评估使用顶点框架并集中于关键情绪:CASME 包含 195 个样本,涉及 8 个类别,重点关注 4 个主要标签(紧张、厌恶、抑郁和惊讶);CASME II 包含从 26 名受试者中收集的 247 个样本,重点关注 5 个主要标签(快乐、惊讶、厌恶、抑郁和其他);SAMM 包含 159 个样本,评估仅限于 10 个标签中的一个(紧张、厌恶、抑郁和其他)。SAMM包含159个样本,评估仅限于10个或更多样本中的标签(愤怒、蔑视、快乐、惊喜、其他)。
动态面部情绪识别侧重于更具挑战性的图像序列。这项任务使用了四个基准数据集(FERV39k、RAVDESS、eNTERFACE05 和 DFEW)。前三个数据集采用官方的训练/验证/测试分割,并评估官方测试集上的性能;DFEW 有五个折叠,包含 11,697 个样本,只报告折叠 1 (fd1) 的结果,以降低评估成本。折叠 1 (fd1)�
此外,多模态情感识别旨在整合音频、视频和文本等不同模态来识别情感。这项任务使用了三个基准数据集(CH-SIMS、CMU-MOSI 和 MER-MULTI):CH-SIMS 和 CMU-MOSI 为每个样本提供情绪强度评分,评估集中在负面/正面分类任务上;MER-.MULTI 是 MER2023 数据集的子集,提供离散和维度标签。MULTI 是 MER2023 数据集的一个子集,为每个样本提供离散和维度标签。本文的重点是离散情绪识别性能。
GPT-4V 通话策略
本文评估了最新 GPT-4V 应用程序接口 gpt-4-vision-preview 的性能。广义情感识别任务涉及多种模式,包括图像、文本、视频和音频,但当前的 GPT-4V 版本存在局限性,仅支持图像和文本输入。要处理视频数据,需要对视频进行采样并转换成多幅图像。对于音频数据,有人尝试将其转换为熔谱图,但 GPT-4V 无法对这种输入做出适当的响应。因此,在本文中,我们将评估重点放在图像、文本和视频上,并提出了逐批调用策略和递归调用策略,以解决 API 请求的局限性,减少因安全检查而导致的拒绝情况。
当前的 GPT-4V API 有三个请求限制:每分钟令牌次数 (TPM)、每分钟请求次数 (RPM) 和每日请求次数 (RPD)。这就对提示设计提出了额外的要求。
为了解决 RPM 和 RPD 限制问题,根据以往的研究采用了批量输入的方法。也就是说,向 GPT-4V 输入多个样本,并请求为每个样本生成一个响应。但是,批量大可能会导致令牌总数超过 TPM 限制。此外,这还会增加任务的难度,并可能导致错误输出。例如,一个包含 30 个样本的批次可能只能得到 28 个预测结果。因此,图像级输入的批量大小设置为 20,视频级输入的批量大小设置为 6,以确保同时满足 TPM、RPM 和 RPD 这三个 API 限制。
每项任务的提示如下表所示。

在评估过程中,GER 任务也往往会触发 GPT-4V 的安全检查。这与视觉情绪分析和人类情绪识别任务有关。前一项任务涉及暴力图像,而在后一项任务中,人的身份被视为敏感信息。
为了减少这些错误,GPT-4V 被要求在提示时忽略说话者的身份。但是,安全错误仍可能发生。这些错误是随机发生的。例如,尽管所有图像都是以人为中心的,但有些图像会通过安全检查,有些则会失败。另外,一个样本可能第一次检查失败,但重试时会通过。对同一批次进行多次调用可减少拒检情况的发生。
此外,如果输入的批次未通过安全检查,将其分成较小的部分可能会使其通过检查。因此,对于一直未通过的批次,会将其拆分成两个较小的迷你批次,然后将这些迷你批次输入 GPT-4V。这一操作会重复进行,直到无法再分割为止。这种策略被称为 “递归调用策略”,其算法如下。

实验结果
首先,它报告了不同方法在五项广义情感识别任务中的表现。其中包括两种启发式基线:随机猜测和多数猜测。随机猜测法是从候选类别中随机选择标签,而多数猜测法则选择最常见的标签。两种基线都进行了十次实验,并报告了平均结果。
下表显示了视觉情感分析的结果,表明 GPT-4V 在大多数数据集上的表现都优于监督系统。之所以能取得如此优异的成绩,是因为 GPT-4V 具备强大的图像内容理解和推理能力,能准确推断出图像所唤起的情感状态。
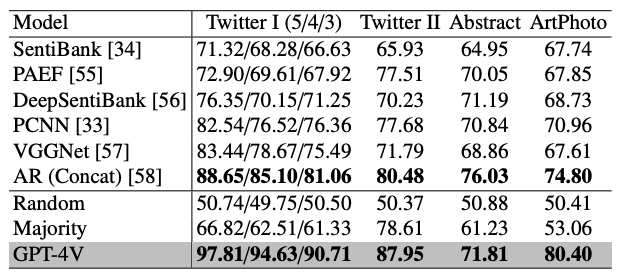
下表显示了微表情识别的结果,其中 GPT-4V 的表现比启发式基线差。这表明,GPT-4V 是为普通大众能够识别的情绪而设计的,并不适合需要专业知识的任务。

动态面部情绪识别、多模态情绪识别可识别视频中的情绪,但由于 GPT-4V 不支持视频输入,它只能从视频中均匀采样帧并按顺序输入。降低了调用成本。下表显示了面部情绪识别的结果。
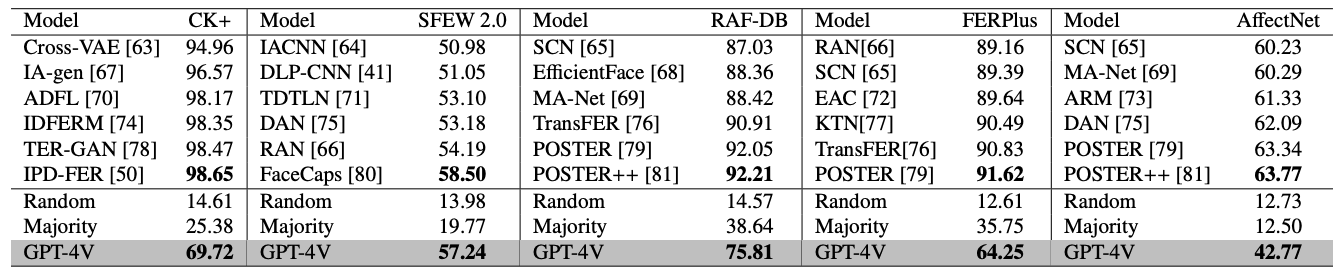
尽管 GPT-4V 和监督系统之间仍存在性能差异,但值得注意的是,GPT-4V 的性能明显优于启发式基线。这些结果证明了 GPT-4V 在情感识别方面的潜力。下表显示了动态面部情绪识别的结果。
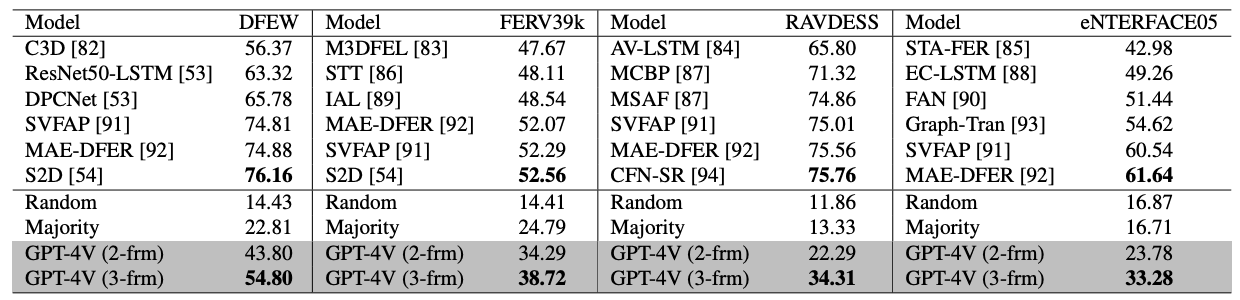
下表是多模态情感识别的结果,其中GPT-4V 在 CMU-MOSI 中表现良好,而在 MER-MULTI 中表现相对较差。造成这种差异的原因是,在 MER-MULTI 中,声音信息比 CMU-MOSI 更为重要;由于 GPT-4V 不支持语音输入,因此在 MER-MULTI 中会丢失信息,从而限制了其性能。
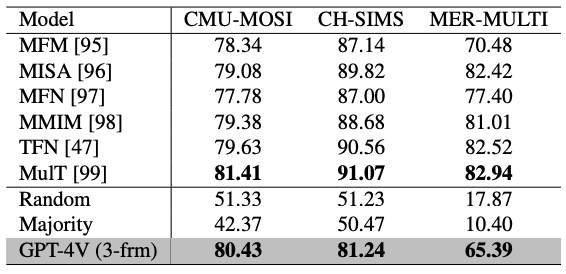
此外,还对 GPT-4V 的多模态理解能力进行了评估。在所有任务中,只有多模态情感识别能提供多模态信息,因此对该任务进行了实验。下表报告了单模态和多模态结果:对于 CH-SIMS 和 MER-MULTI,多模态结果优于单模态结果,这表明 GPT-4V 具有多模态整合能力。然而,对于 CMU-MOSI,多模态结果略低于单模态结果。这是因为 CMU-MOSI 主要依靠词汇信息来传达情感,加入视觉信息可能会造成干扰。
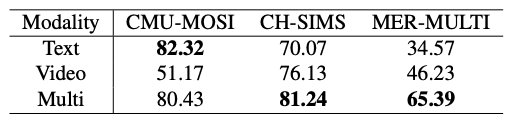
总结
本文全面评估了 GPT-4V 在通用情绪识别任务中的表现:GPT-4V 表现出非常出色的视觉理解能力,在视觉情绪分析方面优于有监督系统。但是,在需要专业知识的微表情识别方面,GPT-4V 表现不佳。
此外,还介绍了 GPT-4V 的时间建模和多模态融合能力及其对色彩空间变化的稳健性。此外,还评估了预测的一致性和安全检查的稳定性,并将错误案例可视化,以突出情感理解的局限性。
此外,它还可作为一个零射基准,为今后的情感识别和多模态大规模语言建模研究提供指导。今后,我们打算扩大评估范围,纳入更多与情感相关的任务和数据集。
注:
论文地址:https://arxiv.org/abs/2312.04293v2
源码地址:https://github.com/zeroQiaoba/gpt4v-emotion.git