文章目录
Lucene_1">第1章 Lucene概述
Lucene是apache软件基金会 jakarta项目组的一个子项目,是一套用于全文检索和搜寻的开源程式库,由Apache软件基金会支持和提供。其作者是大名鼎鼎的大数据之父Doug-Cutting。Lucene通过使用倒排索引技术,能够快速地从大量的文档中检索出相关信息。对文本数据进行高效的索引和搜索,支持复杂的查询语法,包括布尔运算、短语搜索、模糊搜索等。
在Java开发环境里Lucene是一个成熟的免费开源工具。就其本身而言,Lucene是当前以及最近几年最受欢迎的免费Java信息检索[程序库。人们经常提到信息检索程序库,虽然与搜索引擎有关,但不应该将信息检索程序库与搜索引擎相混淆。Java中著名的搜索引擎ElasticSearch、Solr等都是采用Lucene作为内核进行开发;
- Lucene官网:https://lucene.apache.org/
Lucene的应用场景如下:
- 网站搜索:许多网站使用Lucene或其衍生产品(如Elasticsearch)来提供站内搜索功能。
- 企业级搜索:在企业内部,Lucene可用于构建文件、邮件、数据库记录等信息的搜索引擎。
- 日志分析:对于大规模的日志数据,可以通过Lucene快速定位到特定的错误或异常信息。
- 电子商务:在线购物平台经常利用Lucene来优化商品搜索体验,提高用户满意度。
1.1 搜索的实现方案
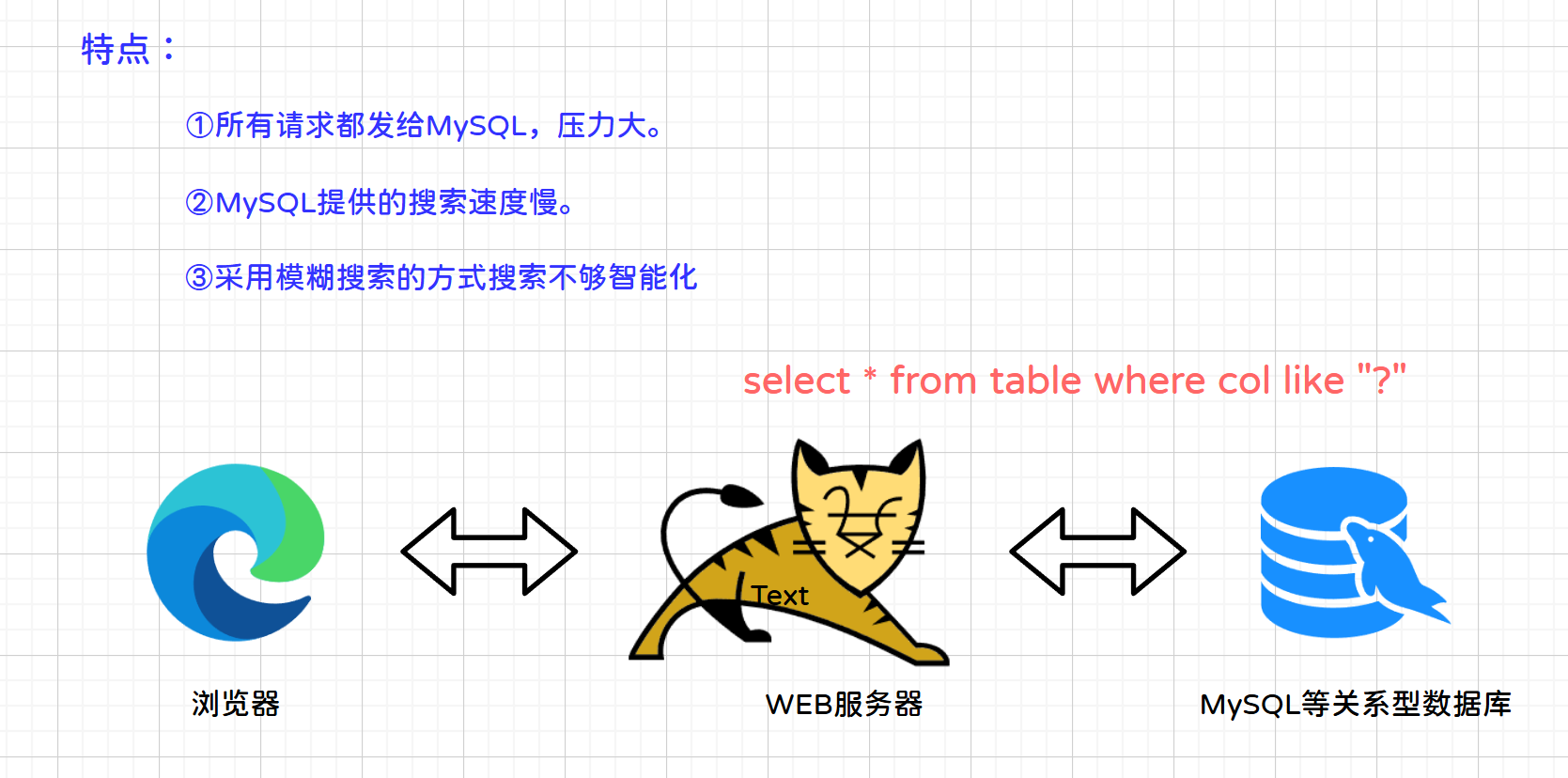
1.1.1 传统实现方案
用户发送请求查询到服务器,服务器通过SQL查询数据库将结果返回,最终将结果集响应到用户。
特点:数据库服务器压力大,查询速度慢,搜索不智能化。
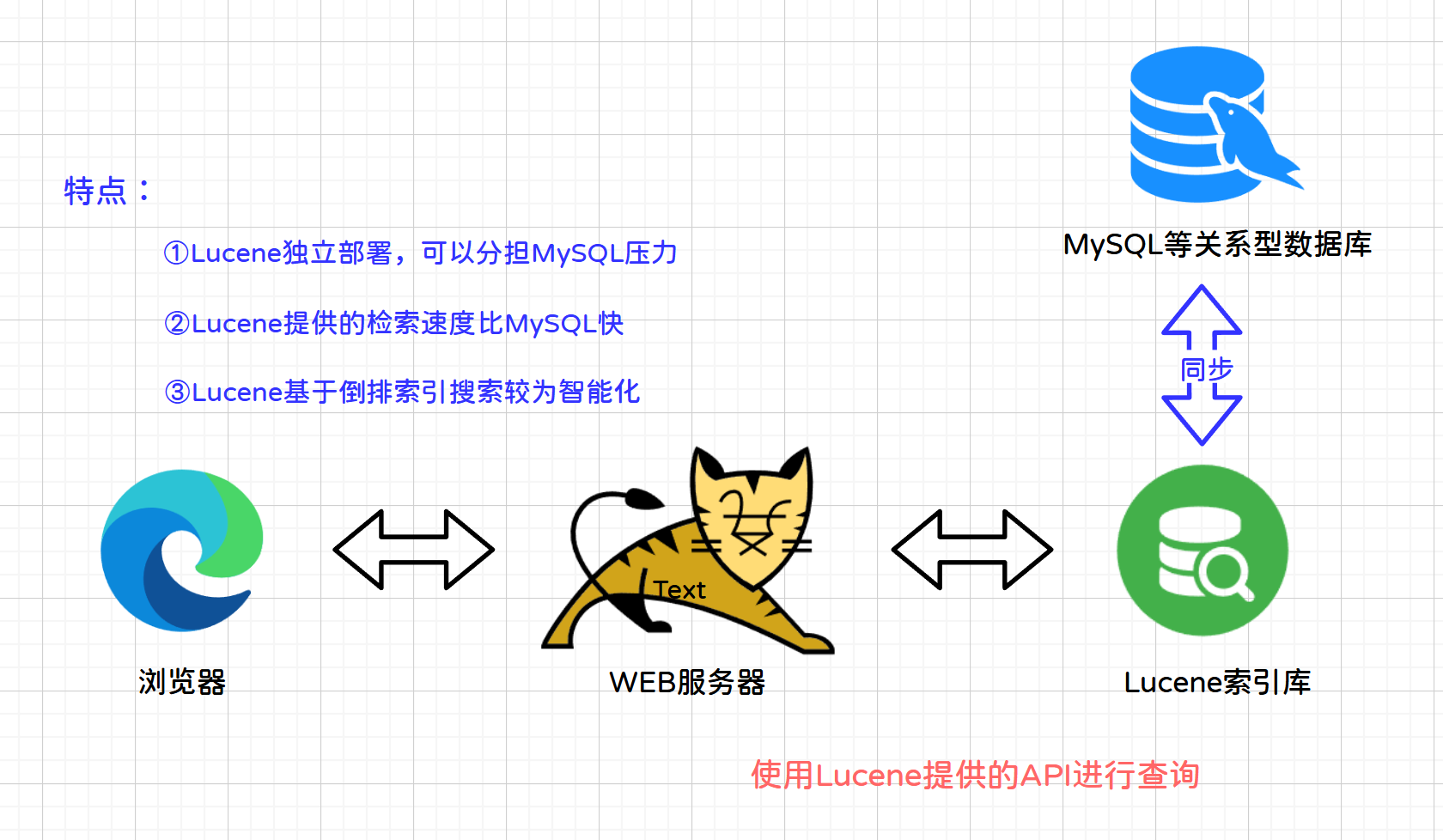
Lucene_30">1.1.2 Lucene实现方案
说明:根据用户输入的搜索关键词(java),应用服务器通过lucene的API搜索索引库,索引库把搜索结果响应应用服务器,应用服务器再把搜索结果响应给用户。
特点:解决用户量大,数据量很大,系统对搜索速度要求高并且需要智能化搜索的业务需求。
1.2 数据查询方法
1.1.1 顺序扫描法
举个例子:比如我们有大量的文件,文件编号从A,B,C。。。。。。
需求:要找出文件内容中包含有java的所有文件
需求实现:从A文件开始查找,再找B文件,然后再找C文件,以此类推。。。。。
特点:如果文件数量很多,查找将会非常慢。
1.1.2 倒排索引法
举个例子:使用新华字典查找汉字,先找到汉字的偏旁部首,再根据偏旁部首对应的目录(索引)找到目标汉字。这个目录在计算机中被称为索引,是用来帮助程序快速查询数据用的。
索引的组织方式有很多,底层结构也不一样,但无论是那种索引都只有一个目标,那就是用于提高查询性能,快速定位到目标数据所在。
文件一(编号0):I am Chinese I am Chinese
文件二(编号1):I love China
| Term | (Doc,Freq) |
|---|---|
| Chinese | (0) (2) |
| love | (1)(1) |
| china | (1)(1) |
说明:
Lucene_74">1.3 Lucene相关概念
使用Lucene的第一步我们需要采集原始数据,数据的来源可以是传统的关系型数据库、文本文件、网络资源等;
- 保存在关系数据库中的业务数据MySQL:通过JDBC操作获取到关系数据库中的业务数据(mysql)
- 保存在文件中的数据:通过IO流获取文件上的数据
- 网络上的网页文件数据:通过爬虫(蜘蛛)程序获取网络上的网页数据
1.3.1 文档对象
文档对象(Document):一个文档对象包含有多个域(Field)。一个文档对象就相当于关系数据库表中的一条记录,一个域就相当于一个字段。

1.3.2 域对象
在Lucene中,一篇文档对应数据库的一行数据,一个域对象则对应一个字段,一个文档由多个域对象组成。在Lucene中不同的域对象具有不同的属性和功能
1)分词
分词(tokenized):对域中的文本内容进行根据要求进行分析,将一段文本分析成一个个符合逻辑的词组;
原始文档:
华为5G智能全面屏拍照游戏手机
分词后:
华为、5G、智能、全面屏、拍照、游戏、手机、游戏手机
- 需要分词的域(Field):商品名称,商品标题。这些内容用户需要输入关键词进行查询,由于内容格式大,内容多,需要进行分词处理建立索引。
- 不需要分词的域(Field):商品编号,身份证号。是一个整体,分词以后没有意义,不需要分词。
2)索引
索引(indexed):对分词后的数据(词组)建立索引关系(建立倒排索引表),索引的目的是为了搜索,最终实现的效果是只需要搜索分词后的词组就能找出对应的文档;
创建索引是对词组单元索引,通过词语找文档,这种索引的结构叫倒排索引结构。
原始文档:
doc-01: 华为5G智能全面屏手机
doc-02: vivo智能5G游戏手机
分词后的数据:
doc-01: 华为、5G、智能、全面屏、手机、全面屏手机
doc-02: vivo、智能、5G、游戏、手机、游戏手机
- 建立的索引(倒排索引表):
| Term | (Doc,Freq) |
|---|---|
| 华为 | (1) (1) |
| 5G | (1) (1) (2) (1) |
| 智能 | (1) (1) (2) (1) |
| 全面屏 | (1) (1) |
| 全面屏手机 | (1) (1) |
| 游戏 | (1) (1) |
| 手机 | (1) (1) (2) (1) |
| 游戏手机 | (2) (1) |
| vivo | (2) (1) |
建立索引其实就是建立词组与文档之间的关系,这个关系表就是倒排索引表,由于倒排索引表中也包含词组,因此索引建立的越多,占用的磁盘空间也会很大;
- 需要建立索引的域:商品名称,商品描述需要分词建立索引。商品编号,身份证号作为整体建立索引。只要将来要作为用户查询条件的词,都需要索引。
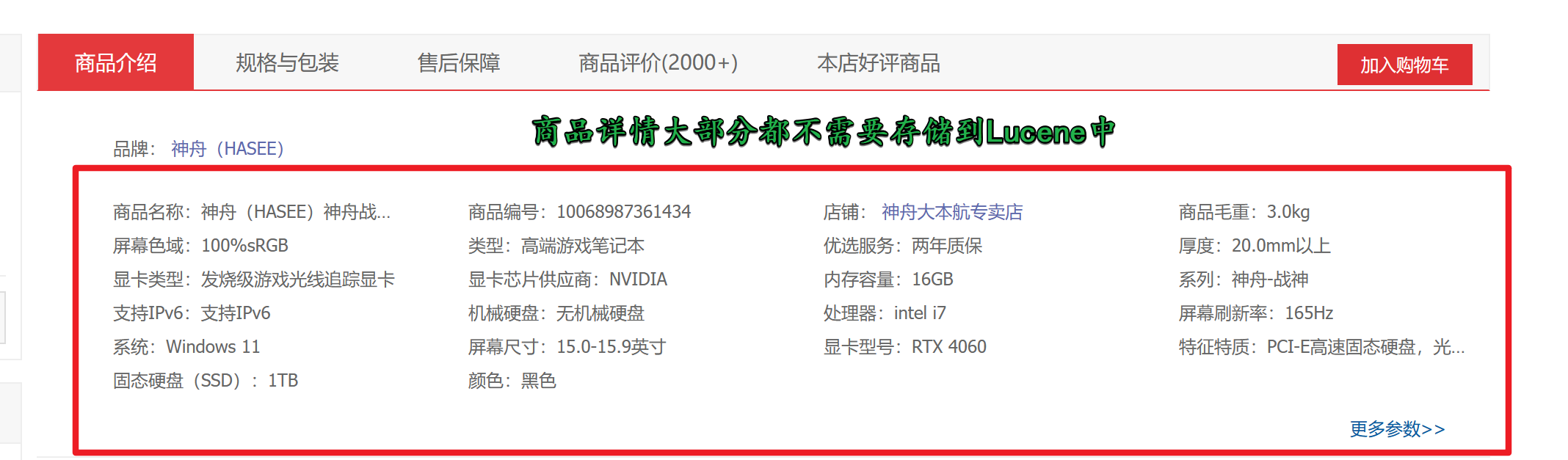
- 不需要建立索引的域:商品图片路径,不作为查询条件,不需要建立索引。
3)存储
存储(stored):由于索引库的数据都是从其他地方采集的(大多数是从关系型数据库中采集),因此其他地方已经存储一份原始数据,因此有些域我们是不需要存储到Lucenen的索引库的,只有那些需要搜索的域我们才存储到Lucene中;
- 需要存储的域:商品名称,商品价格。凡是将来在搜索结果页面展现给用户的内容,都需要存储。
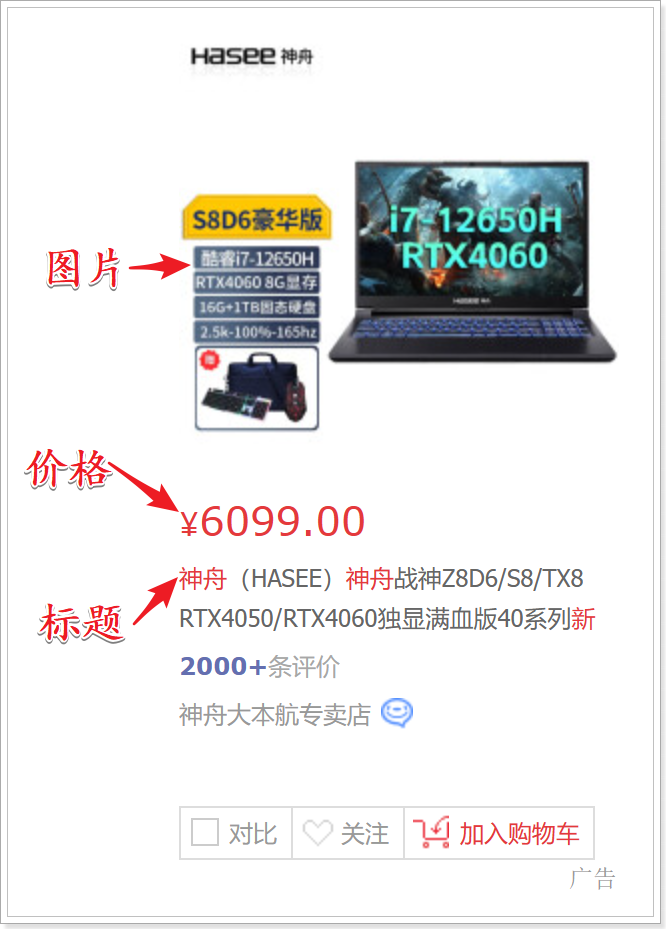
- 不需要存储的域:商品描述。内容多格式大,不需要直接在搜索结果页面展现,不做存储。需要的时候可以从关系数据库取。
1.3.3 常用的Field种类
| Field种类 | 数据类型 | 是否分词 | 是否索引 | 是否存储 | 说明 |
|---|---|---|---|---|---|
| StringField(FieldName,FieldValue,Store.YES)) | 字符串 | N | Y | Y或N | 字符串类型Field,不分词,作为一个整体进行索引(比如:身份证号,商品编号),是否需要存储根据Store.YES或Store.NO决定 |
| DoublePoint(FieldName,FieldValue) | 数值型代表 | Y | Y | N | Double数值型Field代表,分词并且索引(比如:价格),不存储 |
| StoredField(FieldName,FieldValue) | 重载方法,支持多种类型 | N | N | Y | 构建不同类型的Field,不分词,不索引,只存储。(比如:商品图片路径) |
| TextField(FieldName,FieldValue,Store.NO) | 文本类型 | Y | Y | Y或N | 文本类型Field,分词并且索引,是否需要存储根据Store.YES或Store.NO决定 |
1.4 分词器
分词器,是将用户输入的一段文本,分析成符合逻辑的一种工具。到目前为止呢,分词器没有办法做到完全的符合人们的要求。和我们有关的分析器有英文的和中文的;
- 英文分词:
英文分词过程:输入文本-关键词切分-去停用词-形态还原-转为小写。
我们知道英文本身是以单词为单位,单词与单词之间,句子之间通常是空格、逗号、句号分隔。因此对于英文,可以简单的以空格来判断某个字符串是否是一个词,比如:I am Chinese,Chinese很容易被程序处理。
- 中文分词:
中文是以字为单位的,字与字再组成词,词再组成句子。中文:我是中国人,电脑不知道“是中”是一个词,还是“中国”是一个词?所以我们需要一定的规则来告诉电脑应该怎么切分,这就是中文分词器所要解决的问题。
- StandardAnalyzer分词器
一元切分法:一个字切分成一个词。
一元切分法“我是中国人”:我、是、中、国、人。扩展字库
- CJKAnalyzer分词器
二元切分法:把相邻的两个字,作为一个词。
二元切分法“我是中国人”:我是,是中、中国、国人。
- SmartChineseAnalyzer 词库分词器
通常一元切分法,二元切分法都不能满足我们的业务需求。SmartChineseAnalyzer,对中文支持较好,但是扩展性差,针对扩展词库、停用词均不好处理。
- IK-analyzer:IK分词器
最新版在 https://code.google.com/p/ik-analyzer/上,支持 Lucene 4.10 从 2006 年 12 月推出1.0 版开始, IKAnalyzer 已经推出了 4 个大版本。最初,它是以开源项目 Luence 为应用主体的,结合词典分词和文法分析算法的中文分词组件。从 3.0 版本开 始,IK 发展为面向 Java 的公用分词组件,独立 于 Lucene 项目,同时提供了对 Lucene 的默认优化实现。适合在项目中应用。
ik分词器本身就是对Lucene提供的分词器Analyzer扩展实现,使用方式与Lucene的分词器一致。
依赖:
<dependency><groupId>com.janeluo</groupId><artifactId>ikanalyzer</artifactId><version>2012_u6</version></dependency>但是IK分词器在2012年就不再更新了,在Lucene 5.4.0版本出现了部分兼容问题,因此我们本次使用的是:
<dependency><groupId>com.github.magese</groupId><artifactId>ik-analyzer</artifactId><version>8.5.0</version></dependency>