💻博主现有专栏:
C51单片机(STC89C516),c语言,c++,离散数学,算法设计与分析,数据结构,Python,Java基础,MySQL,linux,基于HTML5的网页设计及应用,Rust(官方文档重点总结),jQuery,前端vue.js,Javaweb开发,Python机器学习等
🥏主页链接:Y小夜-CSDN博客
目录
jupyter%20notebook%E7%9A%84%E9%BB%98%E8%AE%A4%E6%96%87%E4%BB%B6%E8%B7%AF%E5%BE%84-toc" style="margin-left:0px;">🎯修改jupyter notebook的默认文件路径
🎃打开Anaconda Prompt
jupyter%20notebook%20--generate-config%20%E5%91%BD%E4%BB%A4-toc" style="margin-left:40px;">🎃输入 jupyter notebook --generate-config 命令
🎃使用记事本打开
🎃找到Jupyter Notebook(anaconda)的快捷方式
🎃重启Jupyter Notebook(anaconda)
🎯下载bank marketing数据集。
🎯Pandas的基本使用方法
🎃使用pandas读取数据
🎃使用pandas查看数据描述信息
🎃使用pandas查看数据统计信息
🎯可视化工具的基本使用
🎃使用seaborn绘制直方图
🎃使用seaborn绘制计数图
🎃使用seaborn和matplotlib组件展示多个特征
🎯使用scikit-learn加载并检查数据
🎯使用scikit-learn训练模型并评估
🎯保存并载入训练好的模型文件
🎯可能遇到的问题
jupyter%20notebook%E7%9A%84%E9%BB%98%E8%AE%A4%E6%96%87%E4%BB%B6%E8%B7%AF%E5%BE%84">🎯修改jupyter notebook的默认文件路径
(注:要自己提前下载好Jupyter notebook)
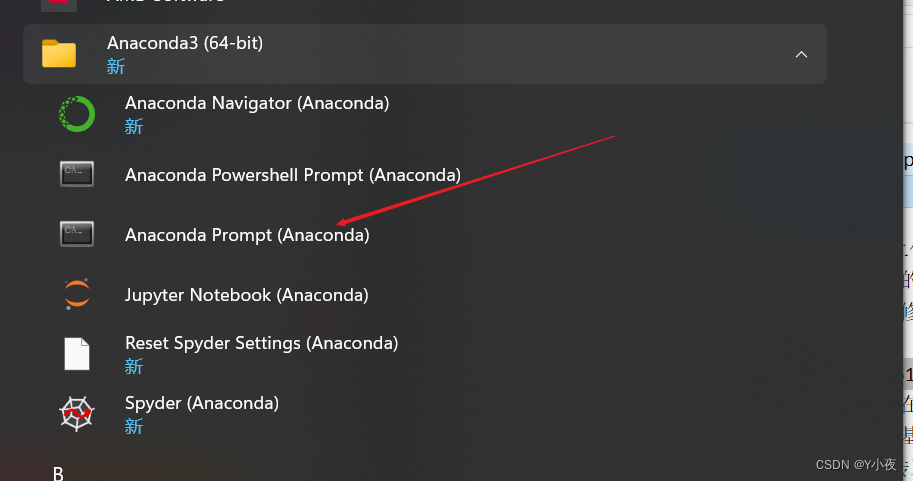
🎃打开Anaconda Prompt
在近几代的win系统中,点击win,并点击所有应用
打开Anaconda Prompt
jupyter%20notebook%20--generate-config%20%E5%91%BD%E4%BB%A4">🎃输入 jupyter notebook --generate-config 命令
从运行结果可知“jupyter_notebook_config.py”的位置


🎃使用记事本打开
找到“#c.NotebookApp.notebook_dir =”的位置
去掉前面的“#”
在单引号' '中添加路径为事先新建的文件夹
然后保存并退出。


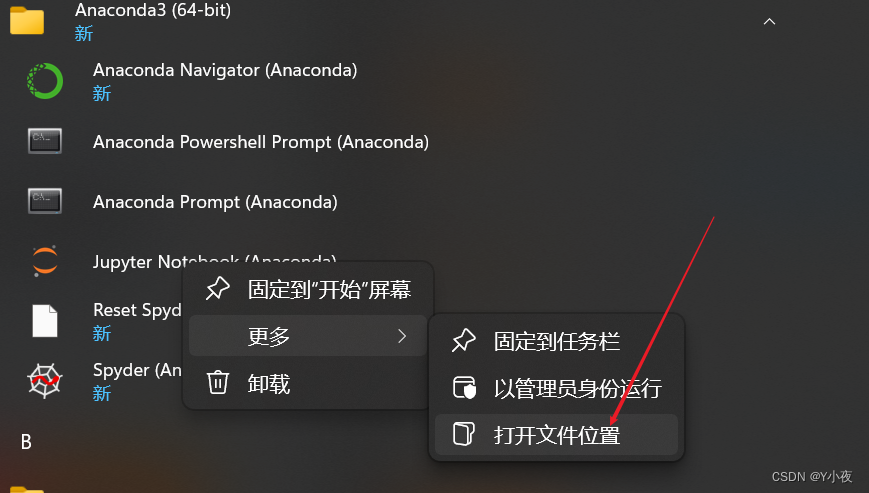
🎃找到Jupyter Notebook(anaconda)的快捷方式
右键鼠标(更多)打开文件位置
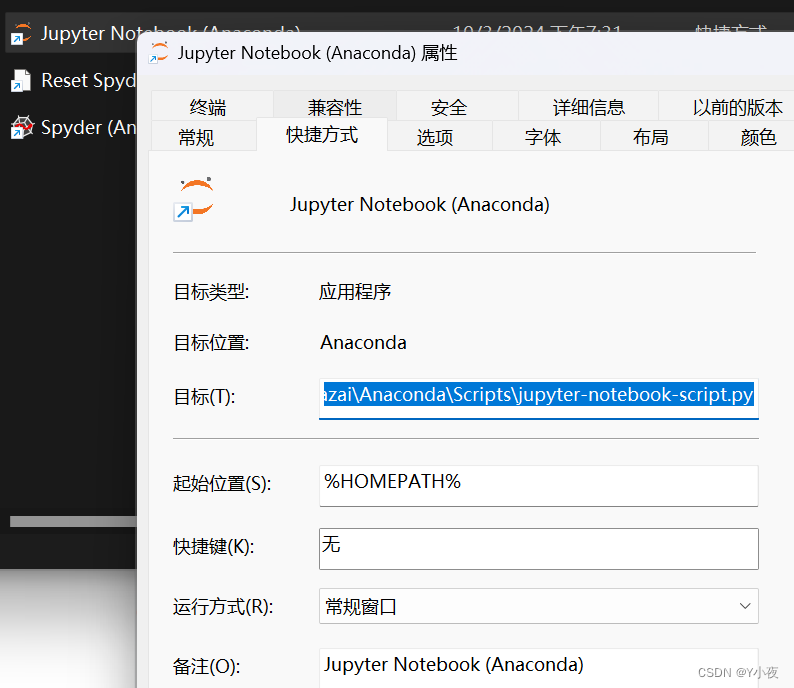
点击属性
在目标一行中,去掉最后面的“%USERPROFILE%/”

🎃重启Jupyter Notebook(anaconda)
可以看到已经成功
如果没有成功,可以再看一下上面的步骤,多试几次。
🎯下载bank marketing数据集。
可以去UCI Machine Learning Repository官网下载
将bank文件夹复制(或上传)到jupyter notebook的实验文件夹中(如果修改过默认路径后,那就放在你修改路径的文件夹下)进行验证:
ok了。



🎯Pandas的基本使用方法
🎃使用pandas读取数据
在数据集下载完毕后,输入一下代码:
import pandas as pd data = pd.read_csv('bank/bank.csv',sep=';') data.head()显示数据前五行的内容

🎃使用pandas查看数据描述信息
data.info()查看数据的描述信息
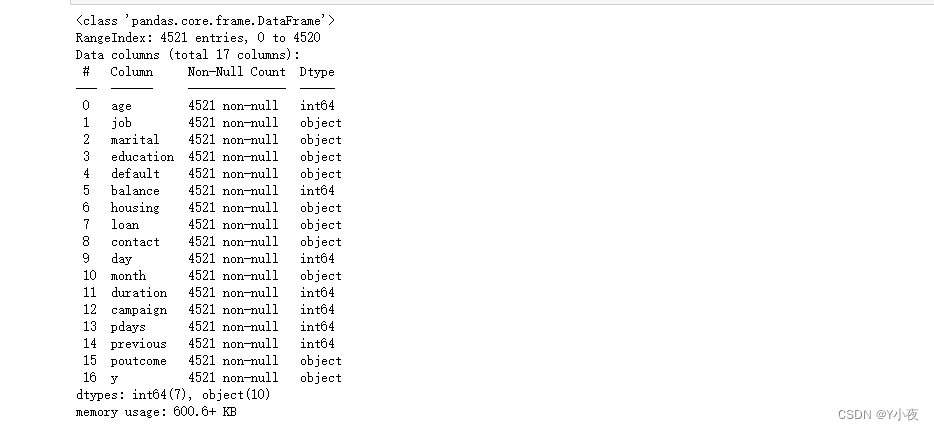
🎃使用pandas查看数据统计信息
data.describe()
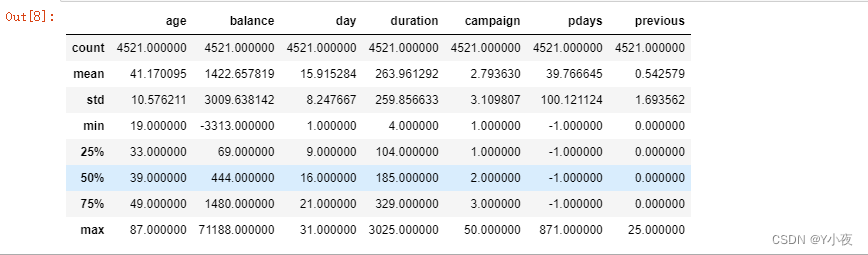
查看样本婚姻状况统计信息
data['marital'].describe()
查看婚姻状况中有哪些不同的数值
data['marital'].unique()

🎯可视化工具的基本使用
🎃使用seaborn绘制直方图
seaborn是一个居于Matplotlib的图形可视化python包,它再matplotlib的基础上进行了更高级的API的封装,是做图更容易。
做一个直方图:
import matplotlib.pyplot as plt import seaborn as sns sns.distplot(data['age']) #如果这一步没有出来图形,那就在运行一个plt.show()

🎃使用seaborn绘制计数图
可以计算字符串类型特征中不同数值出现的次数:
sns.countplot(data['marital'])

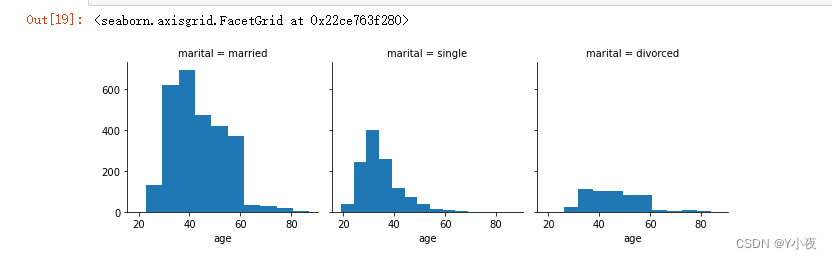
🎃使用seaborn和matplotlib组件展示多个特征
grid=sns.FacetGrid(data,col='marital') grid.map(plt.hist,'age',bins=10)
🎯使用scikit-learn加载并检查数据
scikit-learn内置了一些标准数据集,以供用户来学习和实验。
from sklearn import datasets digits=datasets.load_digits() digits.keys()使用sklearn加载手写数字识别数据集,并查看数据集描述信息。
🎯使用scikit-learn训练模型并评估
from sklearn.model_selection import train_test_split x=digits.data y=digits.target x.shape,y.shape x_train,x_test,y_train,y_test=train_test_split(x,y,random_state=42) x_train.shape,x_test.shape from sklearn import svm clf=svm.SVC() clf.fit(x_train,y_train) clf.score(x_test,y_test)使用sklearn训练模型并评估。

🎯保存并载入训练好的模型文件
import pickle model=open('model.pkl','wb') pickle.dump(clf,model) model.close() model_file=open('model.pkl','rb') clf2=pickle.load(model_file) clf2.predict(x_test[-10:])保存训练好的数据模型,在文件中加载手写数字识别数据集,将训练好的模型导入新文件,直接用加载的模型预测数据集中的最后10个数据,并输出标签中的最后10个标签,对比模型预测的结果是否准确。
🎯可能遇到的问题
- 使用seaborn绘制计数图时,
代码:
sns.countplot(data['marital'])
plt.show()
运行报错:
ValueError: could not convert string to float: 'married'
通过信息错误原因在于marrital由字符串向浮点型转换失败,但上述代码不牵扯到类型的转换,其函数的内部具体是怎么样的也无从得知,通过查阅可知,这是由于版本的更新导致一些数据的输入方式有所改变,如果要保证marital是DataFrame中的一个列名,表示婚姻状态的分类数据,就需要使用data和x参数,将代码改为:
import seaborn as snssns.countplot(x='marital', data=data)
或
sns.countplot(x = data['marital'])
plt.show()
- 在使用scikit-learn训练模型并评估时,使用fit训练第一个模型时,输出结果与预期结果不符,仅为一个两行一列的表格,如下图所示。
通过查阅可知:这是因为从 sklearn 0.22 版本开始,当调用 fit 方法后,除非这些参数从默认值中改变了,否则打印机器学习模型对象将不再显示所有的参数。如果要查看所有的参数,需要直接访问模型的 get_params() 方法:
print(clf.get_params())
这样就可以正常输出各个属性了。