第四章节 loki::allocator
文章目录
- 第四章节 loki::allocator
- 0.概述
- 底层原理
- 工作机制
- 注意事项
- 1、loki的allocator设计
- 0.总体上
- 1. Chunk
- (1)Chunk的结构和初始化
- (2)Chunk的内存分配过程
- (3)Chunk的内存释放过程
- 2. FixedAllocator
- (1)FixedAllocator的结构
- (2)Allocator
- (2)Deallocator
- ① VicinityFind
- ② DoDeallocator
- 3. SmallObjAllocator
- 2、loki::allocator的特点
0.概述
loki::allocator 是 Loki 库中的一个内存分配器组件,但需要注意的是,Loki 库并非 C++ 标准库的一部分,而是一个提供设计模式、编程惯用法等实现的第三方库。由于 Loki 库的具体实现和版本可能有所不同,以下对 loki::allocator 的底层原理和工作机制的描述将基于一般性的理解和假设。
底层原理
loki::allocator 的底层原理主要涉及到内存的分配和释放策略,旨在优化性能和减少内存碎片。它可能采用了以下一些技术:
- 内存池(Memory Pool)
- 内存池是一种预先分配大块内存并在需要时从中分配小块内存的技术。
loki::allocator可能实现了一个或多个内存池,用于存储不同类型的对象。 - 内存池的好处是减少了向操作系统请求内存的次数,从而提高了性能。此外,它还允许分配器更好地控制内存碎片。
- 内存池是一种预先分配大块内存并在需要时从中分配小块内存的技术。
- 对象对齐(Object Alignment)
- 为了满足特定硬件或编译器的要求,
loki::allocator可能支持对象对齐。这意味着对象在内存中的位置将满足特定的对齐条件。 - 对齐通常是为了提高内存访问速度或满足特定数据结构的布局要求。
- 为了满足特定硬件或编译器的要求,
- 自定义分配策略
loki::allocator可能允许用户定义自己的分配策略,如分配大小、对齐要求、是否使用内存池等。- 这提供了灵活性,使得分配器可以根据特定的应用场景进行优化。
- 缓存友好性(Cache Friendliness)
- 为了提高内存访问效率,
loki::allocator可能会尝试将对象分配在缓存友好的位置。 - 这可能涉及到对象的布局、内存池的组织方式以及分配策略的选择。
- 为了提高内存访问效率,
工作机制
loki::allocator 的工作机制通常包括以下几个步骤:
- 内存分配
- 当需要分配内存时,
loki::allocator首先会检查内存池中是否有足够的空闲空间。 - 如果有,它会从内存池中分配一块适当大小的内存给对象。
- 如果没有足够的空闲空间,它可能会向操作系统请求更多的内存,并扩展内存池。
- 当需要分配内存时,
- 对象构造
- 在分配内存之后,
loki::allocator可能会调用对象的构造函数来初始化对象(对于类类型对象而言)。 - 这一步是可选的,取决于分配器的设计和使用场景。
- 在分配内存之后,
- 内存释放
- 当对象不再需要时,
loki::allocator会负责释放对象所占用的内存。 - 它可能会将这块内存归还给内存池,以便将来重新分配。
- 如果内存池已满或不再需要,它可能会将部分或全部内存归还给操作系统。
- 当对象不再需要时,
- 对象析构
- 在释放内存之前,
loki::allocator可能会调用对象的析构函数来清理对象(对于类类型对象而言)。 - 这一步同样是可选的,取决于分配器的设计和使用场景。
- 在释放内存之前,
注意事项
- 由于
loki::allocator不是标准库的一部分,你需要确保你的项目中包含了 Loki 库,并且正确地配置了编译环境。 - 在使用
loki::allocator之前,你应该仔细阅读相关的文档和源代码,以了解它的具体实现和用法。 - 考虑到 Loki 库的使用可能不太广泛,如果你在维护一个长期的项目或与其他开发者合作,使用标准库中的
std::allocator或其他广泛使用的第三方库可能是更安全、更可维护的选择。
1、loki的allocator设计
0.总体上
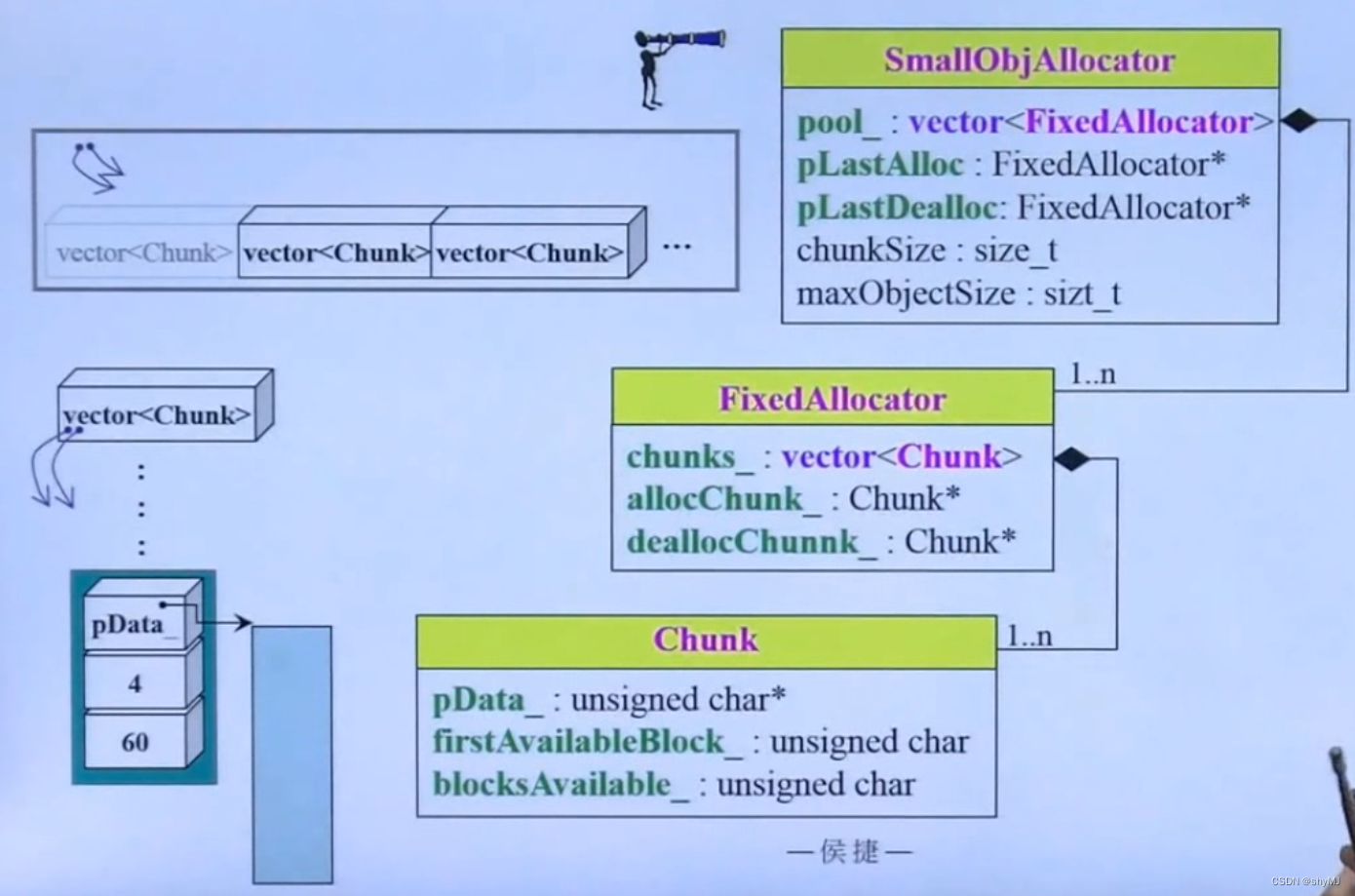
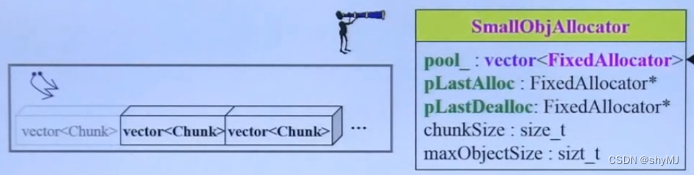
loki::allocator由三个类构成,用户直接操纵SmallObjAllocator。
上面两个类都带有两个指针指向vector对象的类型
1. Chunk
(1)Chunk的结构和初始化
Chunk包含三个部分:一个指针和2个unsigned char。

在chunk初始化时会申请一块内存,然后根据Blocksize将内存切成若干块,由一个指针指向该内存。然后遍历这些内存块,把每个内存块的第一个字节按顺序编号,用这种方式(类似索引)实现嵌入式指针的效果。firstAvailableBlock用于记录下一个可以分配的内存块编号,blocksAvailable_用于记录总共还剩多少个内存块可以分配。

(2)Chunk的内存分配过程
找到firstAvailableBlock记录的可分配内存块,该编号为相对于内存开头的偏移量,这块内存的第一位记录的是下一块优先分配的内存编号,在给出这块内存之前,将firstAvailableBlock指针指向次优先级的内存块,同时blocksAvailable_的值-1。
就是图中的4->3(这个是索引,表示从开头到这块是第几块,3是第四块)就是数字3的块给出去了,如果程序还要继续申请内存那给出去的就会是索引号3,数字块2,再下一个就是索引号2,数字块1。每给出去一块可用的块数就会减一。

(3)Chunk的内存释放过程
回收的块号是回收指针减去头指针再除以块数得到的
先将firstAvailableBlock写入返回内存块的第一位,即最高优先权的位置(在链表里面其实就是个头插法,只不过这里没有虚拟头结点罢了),再根据返回指针的位置,计算出当前内存块的具体位置编号,赋给firstAvailableBlock,最后将blocksAvailable_的值+1。

所以就明白为什么顺序是乱的,因为分配出去的块的顺序和重新回收插入到头部的顺序大多数情况下都不会相同
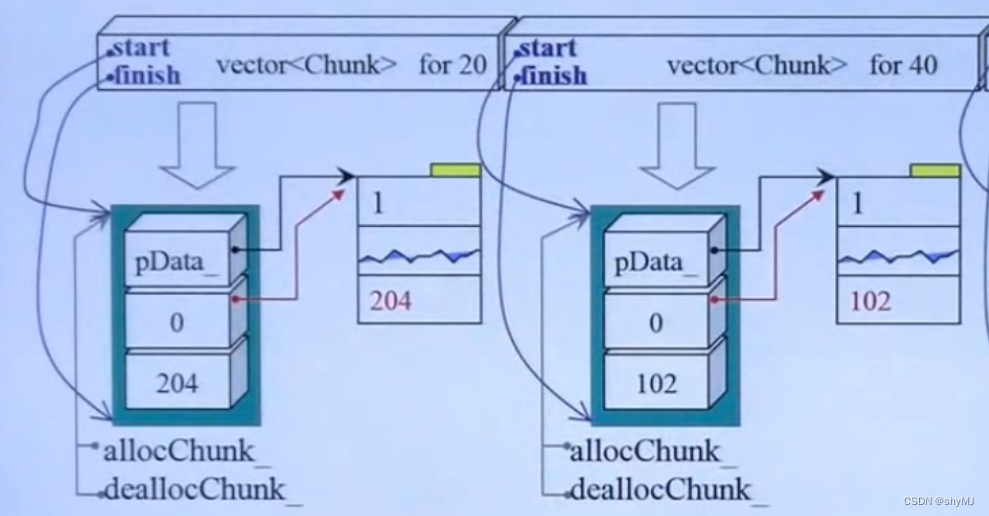
2. FixedAllocator
(1)FixedAllocator的结构
FixedAllocator包含一个vector< Chunk >,allocChunk指针指向的是上一个进行内存分配的chunk,deallocChunk指针指向的是上一个进行内存归还的chunk(根据经验设计的,局部性原理)。

(2)Allocator
首先对allocChunk进行判断,若指针为空或者所指的chunk已经满了,则开始从头遍历chunk。
若遍历结束没找到可用的chunk,则再尾部新增加一个chunk,将allocChunk指向新增的chunk,deallocChunk指向第一个chunk(因为vector可能会搬运move,move之后,原来的指针可能就失效了,所以要重新搞一个值,那索性就第一个好了)。
若遍历过程中找到了可用的chunk,然后直接从该chunk进行内存分配,将allocChunk指向该chunk。还要标记一个哨兵,下次直接从这里开始找Chunk

(2)Deallocator
Deallocator函数进行两个操作,先找到可以归还内存的chunk,再进行chunk全回收判断。

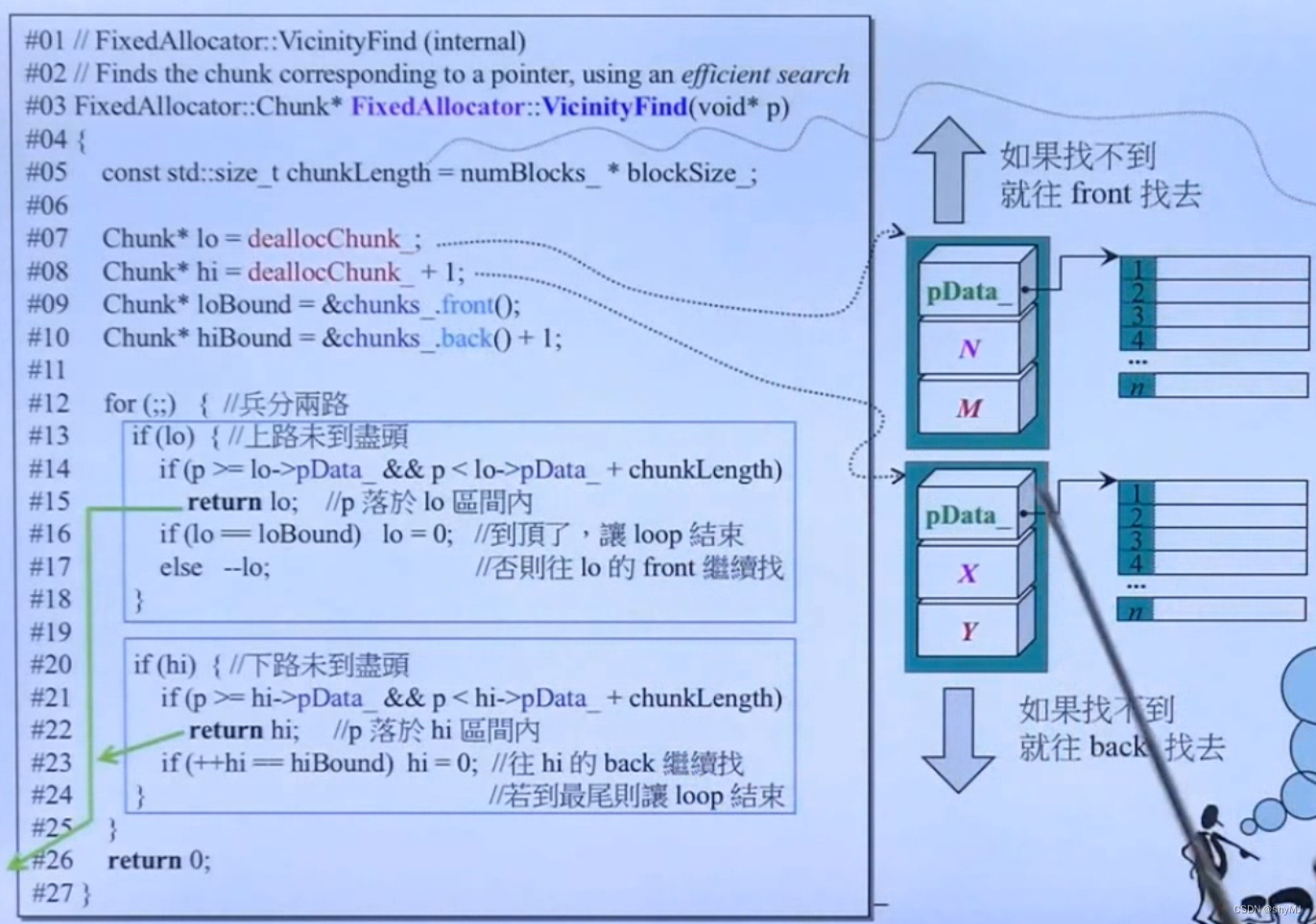
① VicinityFind
定义两个指针分别指向deallocChunk和deallocChunk + 1的chunk,然后从deallocChunk往front找,deallocChunk + 1往back找,交叉寻找(往上找一个chunk,往下找一个chunk),如果找到内存块所属chunk则进入chunk内存返还,若找不到则一直循环!(新版已经改了)
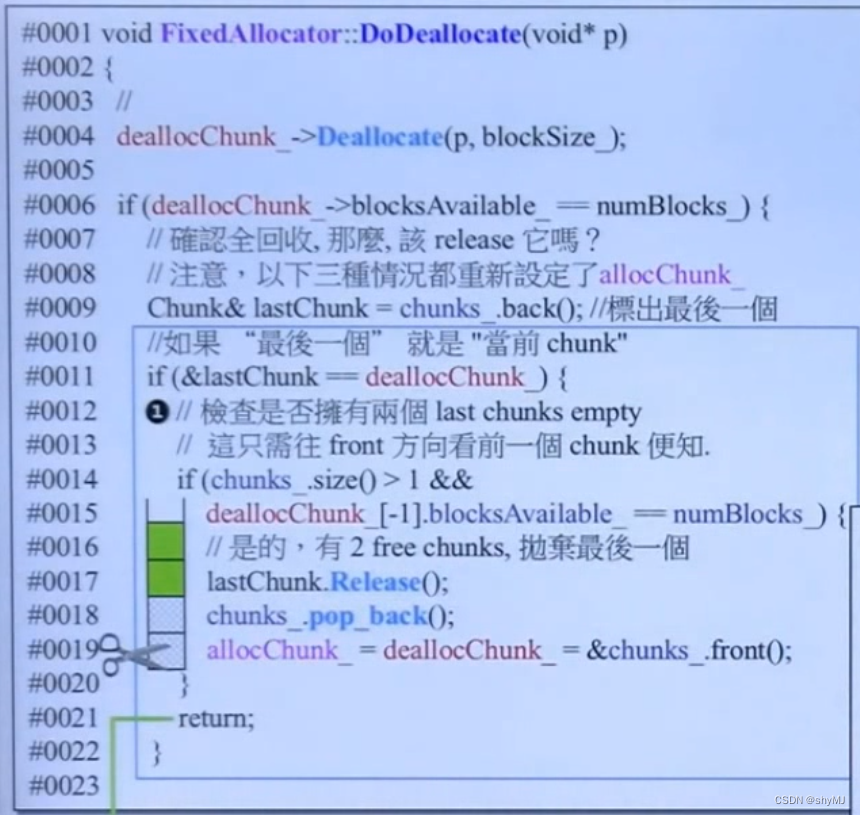
② DoDeallocator
先调用Deallocator进行内存回收,回收完了进行判断,若当前chunk可用空间与初始状态不同,则说明还未全回收,直接跳出程序。若相同,则确认全回收,进行返还判断,分为三种情况:
1.若全回收的chunk为vector的最后一块,并且前一块也是全回收的,则将最后一块chunk释放给系统。
2.若全回收的chunk不为vector的最后一块,但最后一块chunk是全回收的,则将最后一块chunk释放给系统,当前chunk不释放。

3. SmallObjAllocator
SmallObjAllocator是由一系列内存块大小不同的vector< Chunk >组成,主要功能是将程序的内存申请分配到合适大小的vector< Chunk >进行处理。
2、loki::allocator的特点
1.结构简单精简,多使用暴力遍历。
2.使用数组取代链表,索引取代指针的特殊实现。
3.有较为简单的chunk全回收判断,进而归还给系统。
4.有deferring(暂缓归还)功能。
5.本身是个allocator,用于分配不带有cookies的内存块,最适用于容器,但底层却通过vector实现,不太合理,它内部的vector用的分配器还是标准库的那一套而不是他自己这个,要用它自己这个得我们自己写容器的时候指明第二个参数是他这个分配器才行。




