文章目录
- 0. \textbf{0. } 0. 写在前面
- 1. \textbf{1. } 1. 三大类 ANN \textbf{ANN} ANN算法回顾以及 DPG \textbf{DPG} DPG
- 2. \textbf{2. } 2. 实验前
- 3. \textbf{3. } 3. 实验
- 4. \textbf{4. } 4. 试验后
原文章
0. \textbf{0. } 0. 写在前面
0.1. \textbf{0.1. } 0.1. 一些预备知识
1️⃣最邻近查询
- 精确最邻近查询:从数据库中找到与查询对象最近的对象
- 最邻近( NNS \text{NNS} NNS):与查询点最近的唯一点
- k - {k\text{-}} k-最邻近( k-NNS \text{k-NNS} k-NNS):与查询点距离最近的 k k k个点
- 近似最邻近查询:
- 是啥:最邻近查询的 Recall<100% \text{Recall<100\%} Recall<100%版本,即 ANNS/k-ANNS \text{ANNS/k-ANNS} ANNS/k-ANNS
- 原由:高维空间找到精确最邻近很难(突破暴力解法),即所谓维度诅咒(灾难)
- (r,c)-ANN \text{(r,c)-ANN} (r,c)-ANN:给定距离阈值 r r r/查询点 q q q,考虑数据库点 e i e_i ei在 q q q周围 r r r以及 c r cr cr范围的分布

Case \textbf{Case} Case ∃ e i 使D ∈ [ 0 , r ] \exist{}e_i使\text{D}\in[0,r] ∃ei使D∈[0,r] ∃ e i 使D ∈ [ r , c r ] \exist{}e_i使\text{D}\in{}[r,cr] ∃ei使D∈[r,cr] ∃ e i 使D ∈ [ c r , ∞ ] \exist{}e_i使\text{D}\in[cr,\infin{}] ∃ei使D∈[cr,∞] 返回对象 Case 1 \text{Case 1} Case 1 一定 可能 可能 满足 D ≤ c r D\leq{cr} D≤cr的 e i e_i ei Case 2 \text{Case 2} Case 2 不可能 不可能 不可能 寂寞 Case 3 \text{Case 3} Case 3 不可能 一定 可能 满足 D ≤ c r D\leq{cr} D≤cr的 e i e_i ei
- 表中 D=dist ( q , e i ) \text{D=}\text{dist}(q,e_i) D=dist(q,ei)
- 该问题主要应用在基于 LSH \text{LSH} LSH的方法中
2️⃣关于 k -Mean k\text{-Mean} k-Mean算法:
- 什么是 k -Mean k\text{-Mean} k-Mean:将空间分为 k \text{k} k个尽可能内部紧凑/互相远离的部分,分为以下两个阶段
- 数据分配:将每个数据点分给最近的聚类中心,复杂度为 O ( n k ) O(nk) O(nk)
- 重置中心点:重新计算每个聚类的中心点,复杂度为 O ( n ) O(n) O(n)
- 关于 k -Mean k\text{-Mean} k-Mean的大聚类数目
- 是什么:在进行聚类时,选取 k {k} k等于一个很大的数,以至于达到 Θ ( n ) \Theta{}{(n)} Θ(n)规模
- 为何不能 k = Θ ( n ) k\text{=}\Theta(n) k=Θ(n):数据分配复杂度为 O ( n k ) = O ( n 2 ) O(nk)\text{=}O(n^2) O(nk)=O(n2),查询(计算与 k k k个中心距离)为 O ( n ) O(n) O(n)
- 关于如何规避 k = Θ ( n ) k\text{=}\Theta(n) k=Θ(n)则见后续 FLANN / Annoy / OPQ \text{FLANN}/\text{Annoy}/\text{OPQ} FLANN/Annoy/OPQ
0.2. \textbf{0.2. } 0.2. 本文的主要研究
1️⃣在不同领域的数据集上对比不同领域的 ANN \text{ANN} ANN算法
- 当前问题:一些 ANN \text{ANN} ANN的提出只针对特定领域,且只在特定领域的数据集上测试
- 本文工作:选取不同领域的多个最先进算法,在不同领域的多个数据集上测试
2️⃣评估了算法在多种设置和指标下的性能
- 性能类:搜索的时间复杂度,搜索质量(精确度/正确率)
- 资源类:索引大小
- 耐草类:可扩展性,鲁棒性
- 维护类:可更新性,更新参数的成本
3️⃣设计了一种改进新基于图的算法 DPG \text{DPG} DPG
0.3. \textbf{0.3. } 0.3. 本文一些研究限制
1️⃣算法选择:只选择当前最先进的算法,排除被明显超过的其它算法
2️⃣算法实现:注重算法技术本身,削弱实现时的优化 (如取消多线程/多 CPU \text{CPU} CPU等)
3️⃣密集向量:默认向量都密集,不考虑对稀疏数据的特殊处理
4️⃣标签:将每个点的真实 k k k个最邻近点作为标签,以便得到召回率
1. \textbf{1. } 1. 三大类 ANN \textbf{ANN} ANN算法回顾以及 DPG \textbf{DPG} DPG
1.1. \textbf{1.1. } 1.1. 基于哈希的:高维数据 → \to →低维哈希码
1.1.1. LSH \textbf{1.1.1. LSH} 1.1.1. LSH:有理论保证
1️⃣ LSH \text{LSH} LSH原理:当对于 e i , e j e_i,e_j ei,ej哈希函数的选择是随机和独立的( CIKM’13 \text{CIKM'13} CIKM’13),则以下
输入点 e i , e j e_i,e_j ei,ej → 局部敏感哈希函数 \xrightarrow{局部敏感哈希函数} 局部敏感哈希函数 映射结果 相似度高,即 dist ( e i , e j ) < r \text{dist}(e_i,e_j)<r dist(ei,ej)<r → 局部敏感哈希函数 \xrightarrow{局部敏感哈希函数} 局部敏感哈希函数 高概率被映射到相同哈希码上 相似度低,即 dist ( e i , e j ) > c r \text{dist}(e_i,e_j)>cr dist(ei,ej)>cr → 局部敏感哈希函数 \xrightarrow{局部敏感哈希函数} 局部敏感哈希函数 高概率被映射到不同哈希码上 2️⃣ LSH \text{LSH} LSH函数:影响性能的关键
- 针对欧几里得空间的: SCG’04 \text{SCG'04} SCG’04 / FOCS’06 \text{FOCS'06} FOCS’06 / SODA’14 \text{SODA'14} SODA’14 / WADS’07 \text{WADS'07} WADS’07 / STOC’15 \text{STOC'15} STOC’15
- 基于随机线性投影的: SCG’04 \text{SCG'04} SCG’04 / VLDB’99 \text{VLDB'99} VLDB’99 / SODA’06 \text{SODA'06} SODA’06 / SIGMOD’09 \text{SIGMOD'09} SIGMOD’09
3️⃣ LSH \text{LSH} LSH函数及 LSH \text{LSH} LSH方法的改进研究
- LSH \text{LSH} LSH函数的连接:将多个哈希函数首尾相连,但增加了哈希表数量(时空开销)
- 动态 LSH \text{LSH} LSH函数
- 静态 LSH \text{LSH} LSH原理:处理所有点构建哈希表 → \to →哈希表一构建就不变 → \to →执行查询
- 静态 LSH \text{LSH} LSH弊端:哈希表随机构建,会导致与查询点很近的点与查询点不碰撞(被忽略)
- 动态 LSH \text{LSH} LSH:查询时动态地计数和调整碰撞情况, VLDB’07 \text{VLDB'07} VLDB’07 / SIGMOD’07 \text{SIGMOD'07} SIGMOD’07 / SIGMOD’16 \text{SIGMOD'16} SIGMOD’16
- 启发式寻桶
- 咋办:通过启发式方法(靠直觉)检查查询点附近的其它桶, VLDB’07 \text{VLDB'07} VLDB’07 / MM’08 \text{MM'08} MM’08 / VLDB’07 \text{VLDB'07} VLDB’07
- 好处:提高搜索质量同时,不增加哈希表数量(相比连接 LSH \text{LSH} LSH函数)
1.1.2. Learning to Hash(L2H) \textbf{1.1.2. Learning to Hash(L2H)} 1.1.2. Learning to Hash(L2H):无理论保证
1️⃣原理:学习原有数据的分布 → 生成 \xrightarrow{生成} 生成特定哈希,使得原空间中的近似关系在哈希空间得到保留
2️⃣类型:
Type \textbf{Type} Type Pub. \textbf{Pub.} Pub. 成对相似性保持类 ICML’11 \text{ICML'11} ICML’11 / NIPS’08 \text{NIPS'08} NIPS’08 / NIPS’14 \text{NIPS'14} NIPS’14 / KDD’10 \text{KDD'10} KDD’10 / CVPR’13 \text{CVPR'13} CVPR’13 多重相似性保持类 ICCV’13 \text{ICCV'13} ICCV’13 / MM’13 \text{MM'13} MM’13 隐式相似性保持类 CVPR’11 \text{CVPR'11} CVPR’11 / ICCV’13 \text{ICCV'13} ICCV’13 量化类 TPAMI’11 \text{TPAMI'11} TPAMI’11 / TPAMI’13 \text{TPAMI'13} TPAMI’13 / NIPS’12 \text{NIPS'12} NIPS’12 3️⃣关于量化类方法:最有效的 L2H \text{L2H} L2H方法
- 核心:最小化量化失真 (及 min ∑ \min\displaystyle\sum min∑ 每个数据点 ↔ \xleftrightarrow{ } 其最邻近指的差)
- PQ(Product Quantization) \text{PQ(Product Quantization)} PQ(Product Quantization)算法, TPAMI’11 \text{TPAMI'11} TPAMI’11 / TIT’06 \text{TIT'06} TIT’06( Quantization \text{Quantization} Quantization)
- 原理: M \text{M} M维原始向量 → 分割 \xrightarrow{分割} 分割 N \text{N} N个 M N \cfrac{\text{M}}{\text{N}} NM维子向量 → ( 寻求每个子向量最近的质心Index ) 向量量化 \xrightarrow[(寻求每个子向量最近的质心\text{Index})]{向量量化} 向量量化(寻求每个子向量最近的质心Index) N \text{N} N维短代码(向量)
- 改善途径:
Type \textbf{Type} Type Pub. \textbf{Pub.} Pub. 改善 PQ \text{PQ} PQ的索引步骤 TPAMI’13 \text{TPAMI'13} TPAMI’13 / CVPR’13 \text{CVPR'13} CVPR’13 / CVPR’15 \text{CVPR'15} CVPR’15 / ICCV’13 \text{ICCV'13} ICCV’13 / CVPR’14 \text{CVPR'14} CVPR’14 改善 PQ \text{PQ} PQ的搜索步骤 CVPR’14 \text{CVPR'14} CVPR’14 / CVPR’12 \text{CVPR'12} CVPR’12 / ICASSP’11 \text{ICASSP'11} ICASSP’11 / CVPR’16 \text{CVPR'16} CVPR’16 - 扩展 PQ \text{PQ} PQ算法:优化 PQ \text{PQ} PQ( CVPR’14 \text{CVPR'14} CVPR’14),加性量化( CVPR’14 \text{CVPR'14} CVPR’14),复合量化( ICML’14 \text{ICML'14} ICML’14)
4️⃣基于神经网络的(无监督)哈希方法
- Semantic哈希:
- 原理:构建多层 RBM(Restricted Boltzmann Machines) \text{RBM(Restricted Boltzmann Machines)} RBM(Restricted Boltzmann Machines)
- 目标:为文本(文档)学习紧凑的二进制代码
- 如何学习二进制代码
- 通过生成二进制代码:
Type \textbf{Type} Type Pub. \textbf{Pub.} Pub. 设计符号激活层以 CVPR’16 \text{CVPR'16} CVPR’16 / CVPR’15 \text{CVPR'15} CVPR’15 / IJCAI’17 \text{IJCAI'17} IJCAI’17 / TIP’17 \text{TIP'17} TIP’17 提出了约束倒数第二层 ECCV’16 \text{ECCV'16} ECCV’16 - 通过重构数据:使用自编码器作为隐藏层, CVPR’15 \text{CVPR'15} CVPR’15 / IPTA’17 \text{IPTA'17} IPTA’17
- 二进制约束的优化问题
- 成因:必须从哈希函数的输出获得二进制代码,是一个 NP-Hard \text{NP-Hard} NP-Hard问题
- 优化:由 relaxation+rounding \text{relaxation+rounding} relaxation+rounding法使二进制代码次优,如离散优化 NIPS’14 \text{NIPS'14} NIPS’14 / TPAMI’18 \text{TPAMI'18} TPAMI’18
1.2. \textbf{1.2. } 1.2. 基于划分的方法
1️⃣原理:
- 构建:将整个高维空间(递归式)划分为多个不相交的区域
- 核心:默认如果 q q q在 r q r_q rq内,则 q q q的最邻近也在 r q r_q rq(或其附近)
2️⃣空间的划分方式
- 枢轴法( pivoting \text{pivoting} pivoting):
- 根据点 - \text{-} -轴距来划分点: VP-Tree \text{VP-Tree} VP-Tree( SODA’93 \text{SODA'93} SODA’93) / Ball Tree \text{Ball Tree} Ball Tree( ICML’08 \text{ICML'08} ICML’08)
- 超平面法( hyperplane \text{hyperplane} hyperplane):
- 随机方向的超平面:随机投影树( STOC’08 \text{STOC'08} STOC’08)
- 轴对齐的分离超平面:随机 KD \text{KD} KD树( CVPR’08 \text{CVPR'08} CVPR’08/ TPAMI’14 \text{TPAMI'14} TPAMI’14)
- 紧凑法( compact \text{compact} compact):
- 将数据划分为簇: T-C’75 \text{T-C'75} T-C’75
- 创建 Voronoi \text{Voronoi} Voronoi划分: SPIRE’99 \text{SPIRE'99} SPIRE’99 / ICML’06 \text{ICML'06} ICML’06
1.3. \textbf{1.3. } 1.3. 基于图的方法
1️⃣原理:
- 构建:数据 ↔ 对应 \xleftrightarrow{对应} 对应 图结点 + + +数据邻近关系 ↔ 对应 \xleftrightarrow{对应} 对应 图边 → 组成 \xrightarrow{组成} 组成邻近图
- 核心:默认邻居的邻居也是邻居
- 方法:通过迭代扩展邻居的邻居 + + +遵循边的最佳优先搜索策略
2️⃣第一大类:构建近似 KNN-Graph \text{KNN-Graph} KNN-Graph,图中每个节点指向最近的 k k k个邻居
- 在高维空间的应用: IJCAI’11 \text{IJCAI'11} IJCAI’11 / CVPR’12 \text{CVPR'12} CVPR’12 / CoRR’17 \text{CoRR'17} CoRR’17 / WWW’11 \text{WWW'11} WWW’11
- 关于算法初始点:
- 随机初始点:容易陷入局部最优, ComACM’80 \text{ComACM'80} ComACM’80
- 改进工作:让 LSH \text{LSH} LSH( TCYB’14 \text{TCYB'14} TCYB’14) / 随机 KD \text{KD} KD树( CoRR’16 \text{CoRR'16} CoRR’16)生成初始点
3️⃣第二大类: SW(Small-World)-Graph \text{SW(Small-World)-Graph} SW(Small-World)-Graph,图中任两节点可较少步到达 ( Nature’20 \text{Nature'20} Nature’20)
- NSW \text{NSW} NSW方法:通过迭代插入点来构建 SW-Graph \text{SW-Graph} SW-Graph ( IS’14 \text{IS'14} IS’14)
- HNSW \text{HNSW} HNSW方法: NSW \text{NSW} NSW的扩展,最有效的 ANNS \text{ANNS} ANNS算法之一 ( CoRR’16 \text{CoRR'16} CoRR’16)
1.4. \textbf{1.4. } 1.4. 关于 DPG \textbf{DPG} DPG
1.4.1. \textbf{1.4.1. } 1.4.1. 传统 KNN \textbf{KNN} KNN图:连通性较差
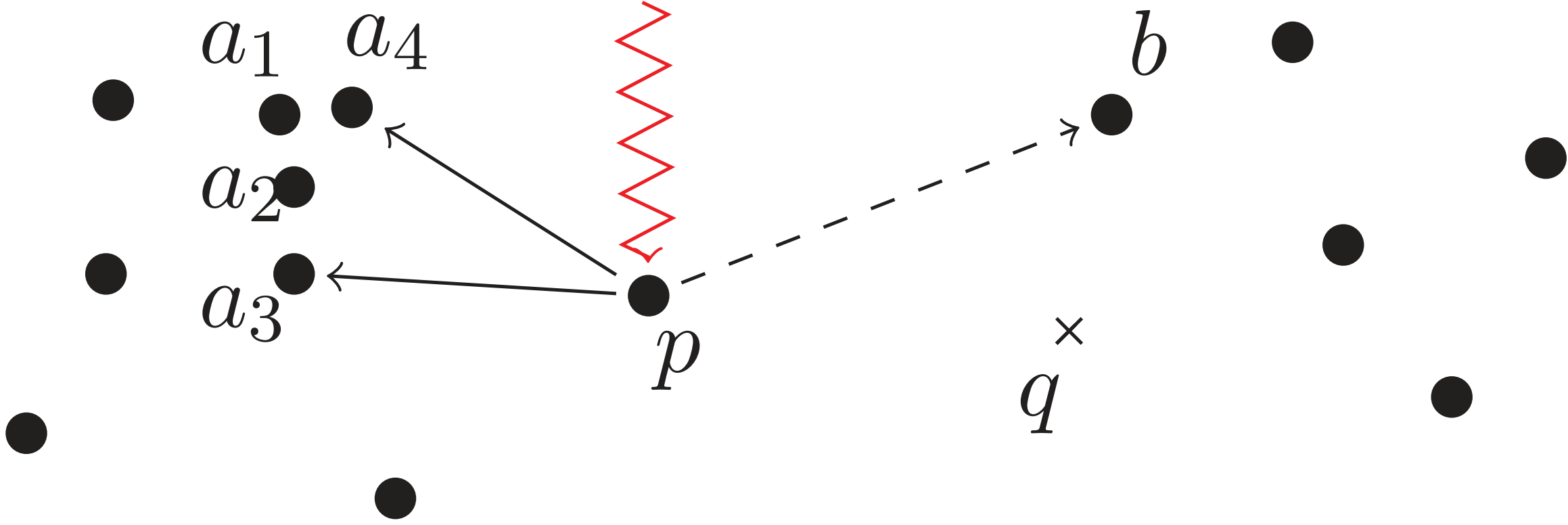
1️⃣原因之一:最邻近聚集在一个方向
- 实例:如下 2-NN \textbf{2-NN} 2-NN图中,搜索路径只能 p → { a 3 , a 4 } p\text{→}\{a_3,a_4\} p→{a3,a4}而不能 p → b p\text{→}b p→b即使 p ↔ b p\xleftrightarrow{}b p b很近
- 咋整:选取邻居时不仅考虑距离,还需考虑角度
2️⃣原因之二:中心性问题
- 是啥: KNN \text{KNN} KNN图中很多的点没有入度,即不作为其他点的最邻近( JMLR’11 \text{JMLR'11} JMLR’11),如上图点 p p p
- 咋整:将单向边变成双向边
1.4.2. DPG \textbf{1.4.2. DPG} 1.4.2. DPG
1️⃣相似度:给定 p p p及其 K K K最邻近列表 L \mathcal{L} L,对于 x , y ∈ L x,y\in{}\mathcal{L} x,y∈L用角度 θ ( x , y ) = ∠ x p y \theta(x, y)\text{=}\angle x p y θ(x,y)=∠xpy衡量 x y xy xy的相似度
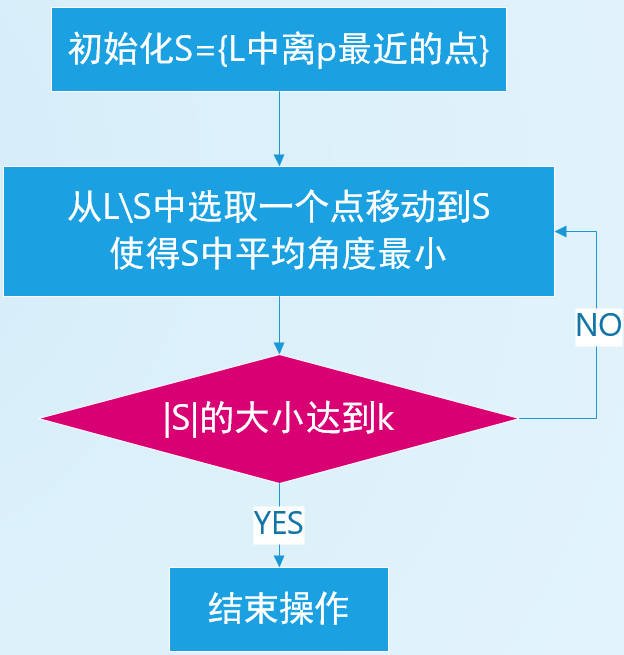
2️⃣ DPG \text{DPG} DPG的构建算法:
- 算法流程
- 对于 p p p,先找出其 K K K个最邻近点(组成 L \mathcal{L} L列表)
- 从 L \mathcal{L} L列表中选择子集 S \mathcal{S} S( | S |= κ \text{|}\mathcal{S}\text{|=}\kappa |S|=κ)使 S \mathcal{S} S中两点平均角度最大;选择方法遵循以下贪婪启发式算法
- 将所有边双向化,即 ∀ u ∈ S \forall{}u\in\mathcal{S} ∀u∈S将 ( p , u ) (p, u) (p,u)与 ( u , p ) (u, p) (u,p)都包括在邻近图中
- 关于构建算法
- 时间复杂度为 O ( κ 2 K n ) O\left(\kappa^2 K n\right) O(κ2Kn),本文也实现了一个简化的性能较差版本复杂度为 O ( K 2 n ) O\left(K^2 n\right) O(K2n)
- 为 | S |= κ \text{|}\mathcal{S}\text{|=}\kappa |S|=κ选取 K K K至关重要,实证表明 K = 2 κ K\text{=}2 \kappa K=2κ最佳
3️⃣搜索过程:与 KGraph \text{KGraph} KGraph的搜索完全相同
2. \textbf{2. } 2. 实验前
2.1. \textbf{2.1. } 2.1. 参与实验的算法
1️⃣基于 LSH \text{LSH} LSH: QALSH \small\text{QALSH} QALSH( VLDB’15 \small\text{VLDB'15} VLDB’15), SRS \small\text{SRS} SRS( VLDB’14 \small\text{VLDB'14} VLDB’14), FALCONN \small\text{FALCONN} FALCONN( NIPS’15 \small\text{NIPS'15} NIPS’15)
2️⃣基于 L2H \text{L2H} L2H:
算法类型 算法 基于二进制 SGH \small\text{SGH} SGH( IJCAI’15 \small\text{IJCAI'15} IJCAI’15), AGH \small\text{AGH} AGH( ICML’11 \small\text{ICML'11} ICML’11), NSH \small\text{NSH} NSH( VLDB’15 \small\text{VLDB'15} VLDB’15) 基于量化 OPQ \small\text{OPQ} OPQ( TPAMI’14 \small\text{TPAMI'14} TPAMI’14), CQ \small\text{CQ} CQ( ICML’14 \small\text{ICML'14} ICML’14) 其它 SH \small\text{SH} SH( SIGKDD’15 \small\text{SIGKDD'15} SIGKDD’15), NAPP \small\text{NAPP} NAPP( VLDB’15 \small\text{VLDB'15} VLDB’15) 3️⃣基于划分的:
- FLANN \text{FLANN} FLANN类: FLANN/FLANN-HKM/FLANN-KD \small\text{FLANN/FLANN-HKM/FLANN-KD} FLANN/FLANN-HKM/FLANN-KD( TPAMI’14 \small\text{TPAMI'14} TPAMI’14), Annoy \small\text{Annoy} Annoy
- VP \text{VP} VP树( TPAMI’14 \small\text{TPAMI'14} TPAMI’14)
4️⃣基于图的:
算法类型 算法 基于小世界的 SW \small\text{SW} SW( IJCAI’15 \small\text{IJCAI'15} IJCAI’15), HNSW \small\text{HNSW} HNSW( CoRR’16 \small\text{CoRR’16} CoRR’16) 基于 KNN \text{KNN} KNN图 KGraph \small\text{KGraph} KGraph( WWW’11 \small\text{WWW'11} WWW’11), DPG \small\text{DPG} DPG(本文) 基于树 RCT \small\text{RCT} RCT( TPAMI’15 \small\text{TPAMI’15} TPAMI’15) 2.2. \textbf{2.2. } 2.2. 数据集与查询负载
1️⃣数据集概述: 18 \text{18} 18个真实数据集(图像/音频/视频/文本) + + + 2 \text{2} 2个合成( Synthetic \text{Synthetic} Synthetic)数据集
Name n ( × 1 0 3 ) d RC LID Type Nus ∗ 269 500 1.67 24.5 Image Gist ∗ 983 960 1.94 18.9 Image Rand ∗ 1 , 000 100 3.05 58.7 Synthetic Glove ∗ 1 , 192 100 1.82 20.0 Text .... . . . . . . . . . . . . . . . . .... \small\begin{array}{cccccc}\hline \text { Name } & n\left(\times 10^3\right) & d & \text { RC } & \text { LID } & \text { Type } \\\hline \text { Nus }^* & 269 & 500 & 1.67 & 24.5 & \text { Image } \\\text { Gist }^* & 983 & 960 & 1.94 & 18.9 & \text { Image } \\\text { Rand }^* & 1,000 & 100 & 3.05 & 58.7 & \text { Synthetic } \\\text { Glove }^* & 1,192 & 100 & 1.82 & 20.0 & \text { Text } \\\text { .... } & .... & .... & .... & .... & \text { .... } \\\hline\end{array}\\{} Name Nus ∗ Gist ∗ Rand ∗ Glove ∗ .... n(×103)2699831,0001,192....d500960100100.... RC 1.671.943.051.82.... LID 24.518.958.720.0.... Type Image Image Synthetic Text ....
2️⃣度量数据集难度的指标
- 相对对比度( RC \text{RC} RC):
- 计算: RC= 每两点距离的平均 每点与其最邻近距离的平均 \text{RC=}\cfrac{\small\text{每两点距离的平均}}{\small\text{每点与其最邻近距离的平均}} RC=每点与其最邻近距离的平均每两点距离的平均
- 含义:较小的 RC \text{RC} RC会导致最邻近不易区分,导致搜索难度变大
- 局部内在维度( LID \text{LID} LID):数据集在某个局部区域的内在维度,越高意味着结构越复杂难以查询
3️⃣查询负载
- 对每个数据集:从每个数据集中移出 200 \text{200} 200个点作为查询点
- 对于 k-NN \text{k-NN} k-NN图算法:进行性能测试时,默认 k=20 \text{k=20} k=20
2.3. \textbf{2.3. } 2.3. 实验设置
2️⃣测试配置
- 选择并使用来自 NMSLIB \text{NMSLIB} NMSLIB库中已经实现的几种算法( NAPP/VP-Tree/SW/HNSW \text{NAPP/VP-Tree/SW/HNSW} NAPP/VP-Tree/SW/HNSW)
- NMSLIB \text{NMSLIB} NMSLIB库:专用于非度量空间的开源库,实现并提供了诸多高维相似性搜索算法
- 度量空间:距离计算具备传统的几何性质,比如欧几里得空间
- 仔细调整了每个算法的超参数
- 关闭了特定的硬件优化,比如禁用 KGraph \text{KGraph} KGraph的多线程等
3️⃣环境:
- 系统: Linux \text{Linux} Linux服务器
- 计算: Intel Xeon e5-2690 + 32G RAM \text{Intel Xeon e5-2690}+\text{32G RAM} Intel Xeon e5-2690+32G RAM
- 编译: C \text{C} C++由 g \text{g} g++ 4.7 \small\text{4.7} 4.7编译, MATLAB \text{MATLAB} MATLAB由 MATLAB 8.5 \text{MATLAB 8.5} MATLAB 8.5编译
2.4. \textbf{2.4. } 2.4. 评估指标
1️⃣查询精度指标:运行算法找到 N \text{N} N个候选最邻近,将 N \text{N} N点按离查询点的距离排序,引出以下指标
- 基础指标:
指标 含义 Recall \text{Recall} Recall N个候选项目中真实最邻近的数目 k \cfrac{\text{N}个候选项目中真实最邻近的数目}{\text{k}} kN个候选项目中真实最邻近的数目 Precision \text{Precision} Precision N个候选项目中真实最邻近的数目 k \cfrac{\text{N}个候选项目中真实最邻近的数目}{\text{k}} kN个候选项目中真实最邻近的数目 F1 Score \text{F1 Score} F1 Score 2 × Precision+Recall Precision+Recall 2\text{×}\cfrac{\text{Precision+Recall}}{\text{Precision+Recall}} 2×Precision+RecallPrecision+Recall - AP(Average Precision) = ∑ i = 1 N [ P(i)×Rel(i) ] N中真实最邻近数量 \text{AP(Average Precision)}=\cfrac{\displaystyle{}\sum_{i=1}^{\small\text{N}}[\text{P(i)×Rel(i)}]}{\text{N}中真实最邻近数量} AP(Average Precision)=N中真实最邻近数量i=1∑N[P(i)×Rel(i)]
- 位置参数 i i i:介于 1→N \text{1→N} 1→N间用于标记候选点, i = 1 i\text{=}1 i=1表示距离查询点最近, i =N i\text{=}\text{N} i=N表示最远
- 相关性标记:将候选 N \text{N} N个最邻近点中,真实的最邻近点标记为相关记作 Rel(i)=1 \text{Rel(i)=1} Rel(i)=1
- 精确率:定义为 P(i)= 截至位置 i 时 , 最邻近的数目 i \text{P(i)=}\cfrac{截至位置i时,最邻近的数目}{ i} P(i)=i截至位置i时,最邻近的数目
- mAP \text{mAP} mAP:就是所有查询点的 AP \text{AP} AP的平均,本文采用此指标
- Accuracy = ∑ i = 0 k dist(q, kANN(q)[i]) dist(q, kNN(q)[i]) \text{Accuracy}=\displaystyle{}\sum_{i=0}^k \cfrac{\text{dist(q, kANN(q)[i])}}{\text{dist(q, kNN(q)[i])}} Accuracy=i=0∑kdist(q, kNN(q)[i])dist(q, kANN(q)[i])参数含义如下,越接近 1 1 1表示最邻近查找越精准
- dist(q, kANN(q)[i]) \text{dist(q, kANN(q)[i])} dist(q, kANN(q)[i]):查询点 ↔ 距离 \xleftrightarrow{距离} 距离 使用某个 ANN \text{ANN} ANN算法排序后第 i i i个最邻近点
- dist(q, kNN(q)[i]) \text{dist(q, kNN(q)[i])} dist(q, kNN(q)[i]):查询点 ↔ 距离 \xleftrightarrow{距离} 距离 真实的第 i i i个最邻近点
2️⃣查询效率(时间)指标:
- 加速比 t ˉ t ′ \cfrac{\bar{t}}{t^{\prime}} t′tˉ:即查询时间比上线性暴力扫描的时间
- 文中还提到了,除了基于图的算法,都可以用调整 N \text{N} N的方法调整查询指标
3️⃣其它指标:
- 索引指标:索引构建时间,索引大小,索引内存
- 可扩展性
3. \textbf{3. } 3. 实验
3.1. \textbf{3.1. } 3.1. 第一轮:类别内评估
1️⃣评估工作:
- 评估流程:
- 评估标准:
- 认为相同召回率下速度提升更大的为更优
- 对于算法数据存在外部的( IO \text{IO} IO次数决定速度),故将总页数/搜索时访问页数作为速率提升
2️⃣评估结果:进入第二轮实验的算法
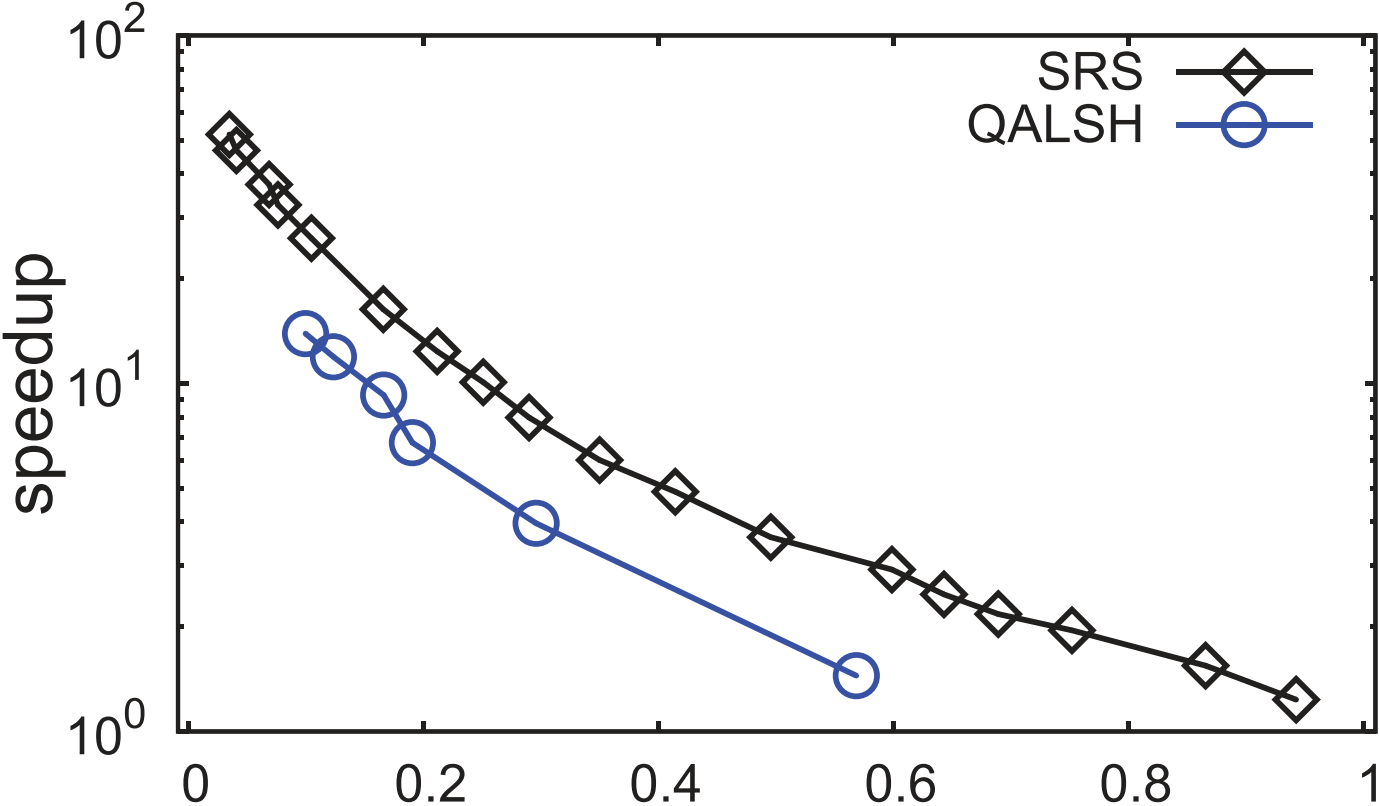
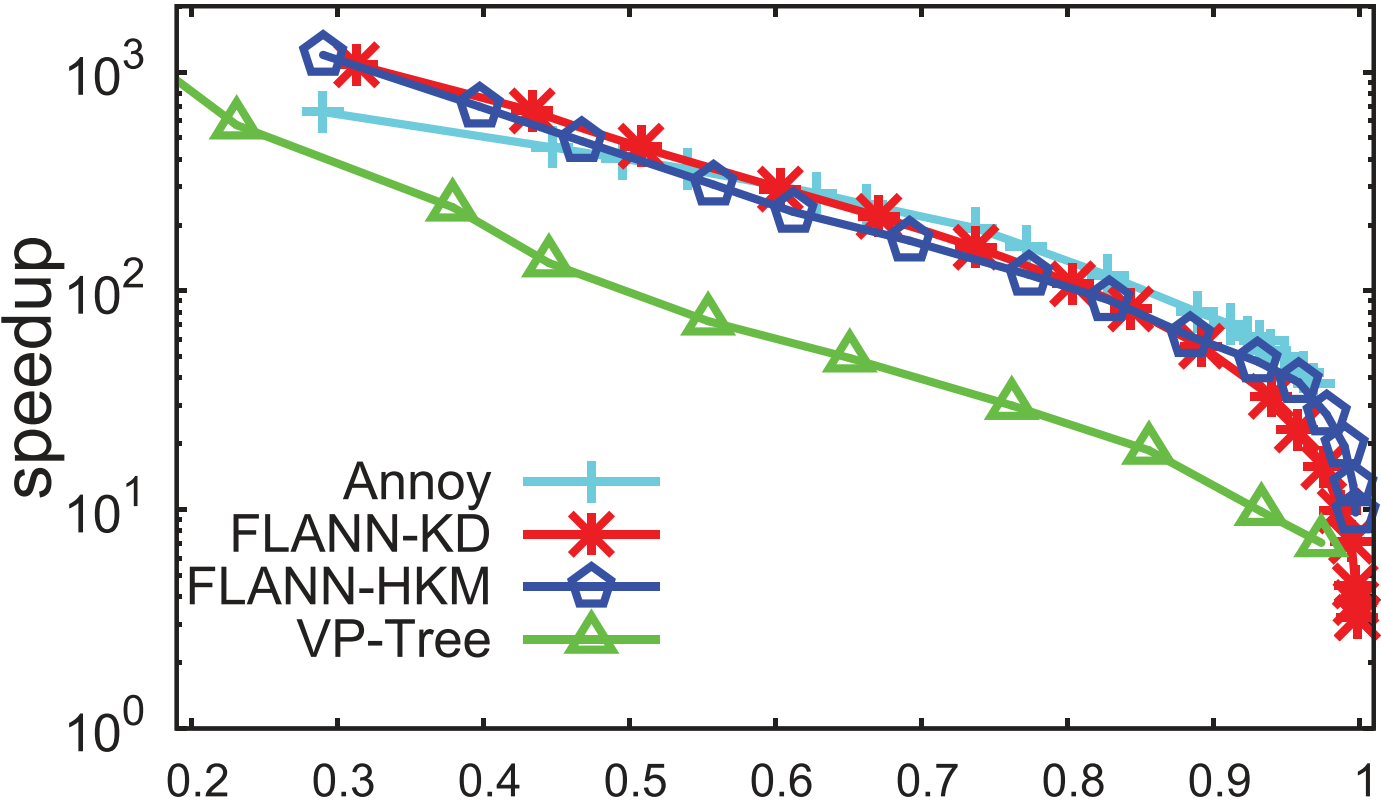
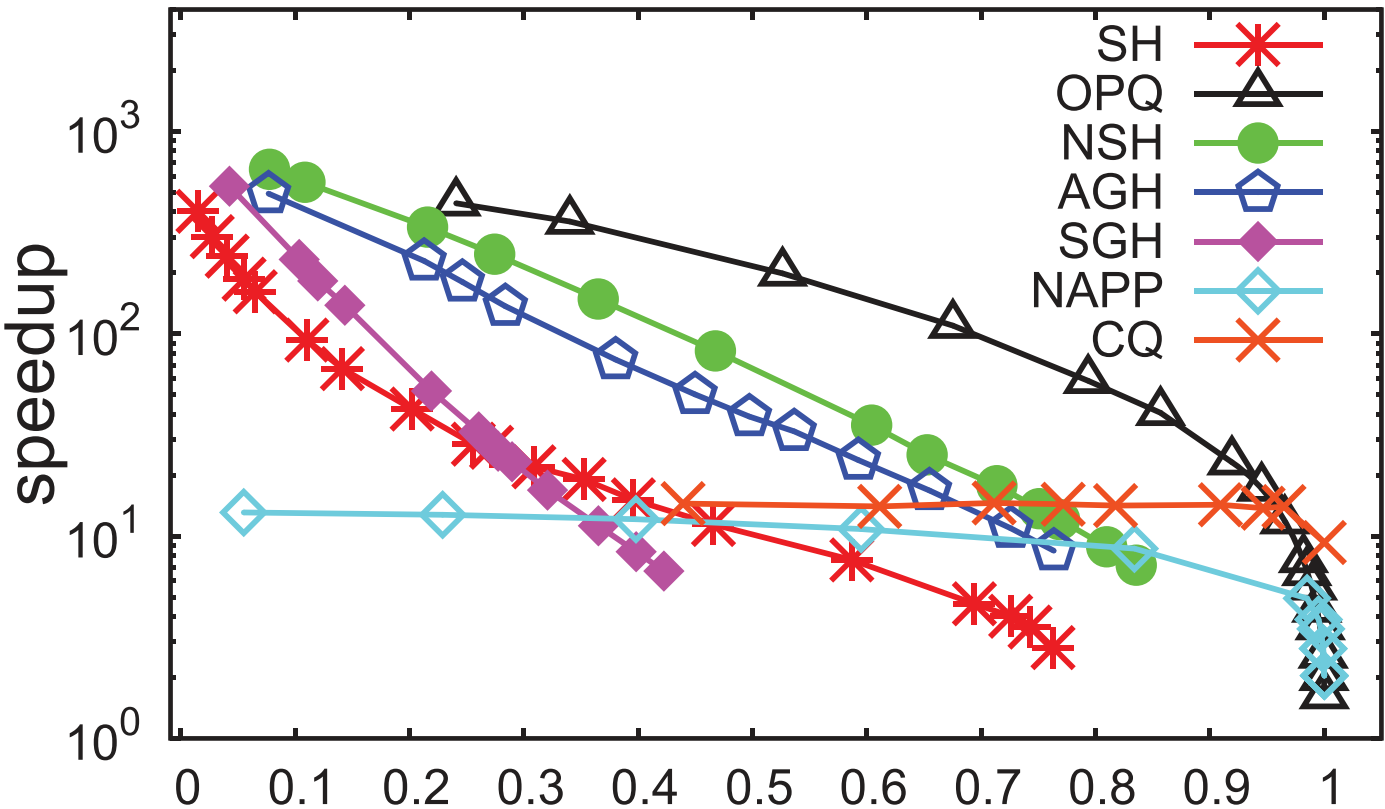
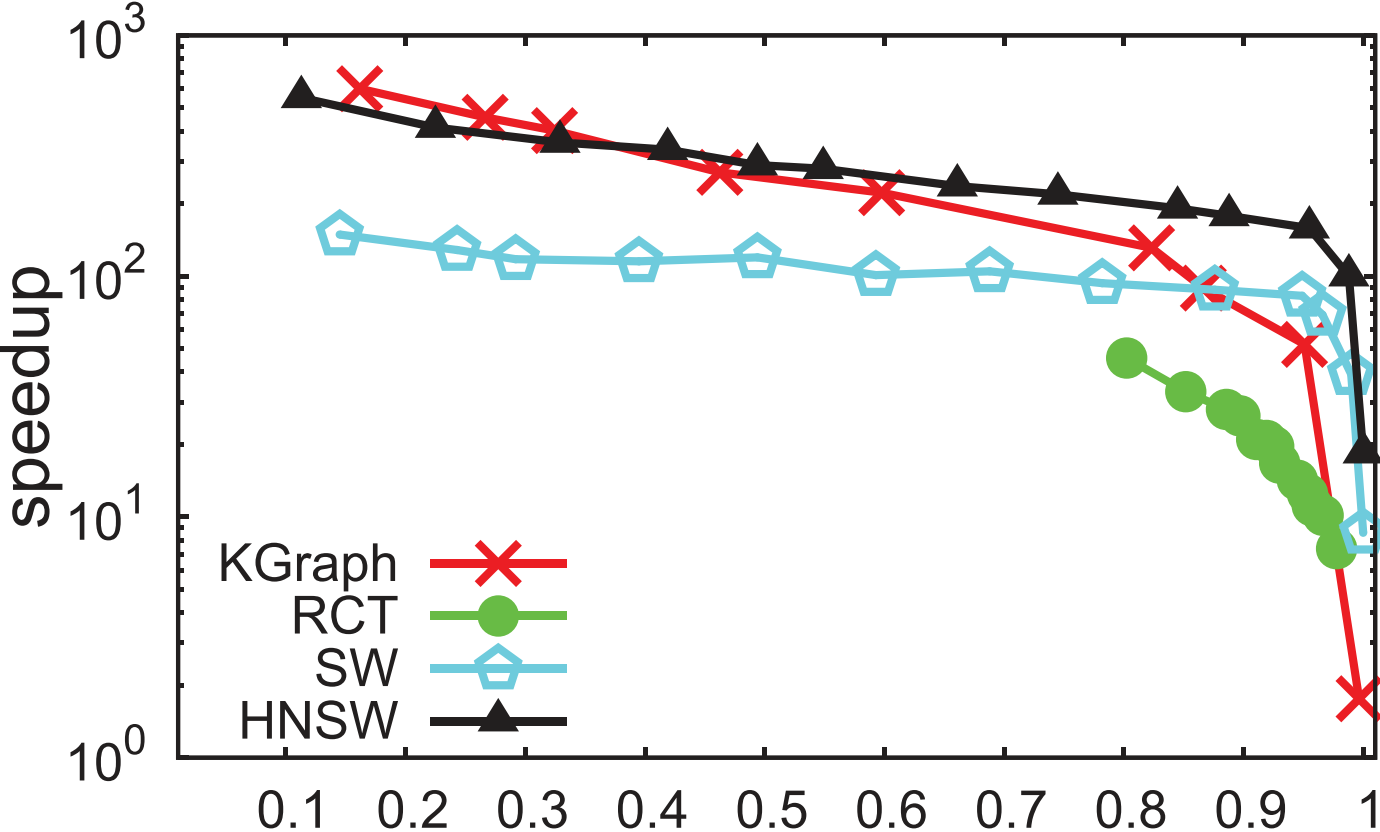
类别 评估选取的结果 LSH \text{LSH} LSH类 SRS/QALSH \text{SRS/QALSH} SRS/QALSH间选取 SRS \text{SRS} SRS, FALCONN \text{FALCONN} FALCONN在 L2 \text{L2} L2距离下性能缺乏保证故放第二轮 L2H \text{L2H} L2H类 选取 OPQ \text{OPQ} OPQ 空间分割类 排除 VP-Tree \text{VP-Tree} VP-Tree 基于图类 选取 KGraph \text{KGraph} KGraph和 HNSW \text{HNSW} HNSW, DPG \text{DPG} DPG延后到下一轮 3.2. \textbf{3.2. } 3.2. 第二轮评估
3.2.1. \textbf{3.2.1. } 3.2.1. 对查询质量/事件的评估
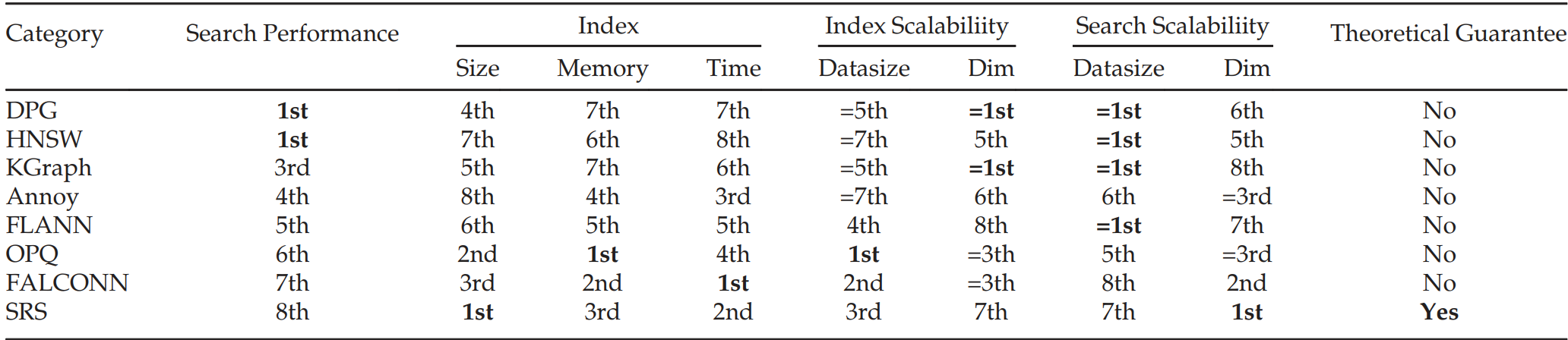
1️⃣加速比 @ Recall=0.8 + Recall @ @\text{Recall=0.8}+\text{Recall}@ @Recall=0.8+Recall@加速比 =50 \text{=50} =50:
- DPG \text{DPG} DPG和 HNSW \text{HNSW} HNSW性能最佳
- 其中 DPG \text{DPG} DPG对 KGraph \text{KGraph} KGraph的改良显著,尤其在难数据集上
- SRS \text{SRS} SRS及其拉跨,源于其没有利用数据集的分布
2️⃣加速比 @ Recall=0→1 @\text{Recall=0→1} @Recall=0→1
- HNSW/KGraph/Annoy \text{HNSW/KGraph/Annoy} HNSW/KGraph/Annoy整体性能优越
- DPG/KGraph \text{DPG/KGraph} DPG/KGraph在高 Recall \text{Recall} Recall下性能优越,但整体不如 HNSW \text{HNSW} HNSW等
3️⃣ Recall @ \text{Recall}@ Recall@访问数据比 = 0 % → 100 % \text{=}0\%\text{→}100\% =0%→100%
4️⃣ Accuracy @ \text{Accuracy}@ Accuracy@ Recall= 0 → 1 \text{Recall}\text{=}0\text{→}1 Recall=0→1:专为 c-ANN \text{c-ANN} c-ANN设计的 SRS \text{SRS} SRS和 FLACONN \text{FLACONN} FLACONN性能优越
3.2.2. \textbf{3.2.2. } 3.2.2. 对索引空间的评估
1️⃣ index size data size \cfrac{\text{index size}}{\text{data size}} data sizeindex size的评估
- 索引大小规模
- 最大: Annoy \text{Annoy} Annoy(大于数据大小),源于其需要维护数量庞大的 Tree \text{Tree} Tree结构
- 最小: OPQ/SRS \text{OPQ/SRS} OPQ/SRS
- 索引大小与维度无关: DPG/KGraph/HNSW/SRS/FLACONN \text{DPG/KGraph/HNSW/SRS/FLACONN} DPG/KGraph/HNSW/SRS/FLACONN
- 索引大小剧烈变化: FLANN \text{FLANN} FLANN,源于其有三种不同索引结构供选择
2️⃣索引构建时间
- 索引时间最小: FALCOMNN \text{FALCOMNN} FALCOMNN,其次是 SRS \text{SRS} SRS
- 索引时间与维度无关: OPQ \text{OPQ} OPQ,源于其涉及子码字的计算
- 相比于 DPG/KGraph \text{DPG/KGraph} DPG/KGraph, DPG \text{DPG} DPG在图的多样化构建上没花太多额外时间
3️⃣索引内存成本: OPO \text{OPO} OPO在索引构建时内存开销低,由此在大规模数集上高效
4. \textbf{4. } 4. 试验后
4.1. \textbf{4.1. } 4.1. 算法选择策略
1️⃣计算/主存足够时:选择 DPG/HNSW \text{DPG/HNSW} DPG/HNSW,其次选 Annoy \text{Annoy} Annoy以在硬件和搜索性能上折中
2️⃣看重索引构建时间时:选择 FALCONN \text{FALCONN} FALCONN
3️⃣处理大规模数据: OPQ/SRS \text{OPQ/SRS} OPQ/SRS,源于二者内存成本/构建时间较小
4.2. \textbf{4.2. } 4.2. 进一步分析:空间划分类算法
1️⃣ k -Mean k\text{-Mean} k-Mean类的 ANN \text{ANN} ANN算法:如何规避 k = Θ ( n ) k\text{=}\Theta(n) k=Θ(n)
- FLANN / Annoy \text{FLANN}/\text{Annoy} FLANN/Annoy(递归树思想):每个结点将数据划为 k k k块(子节点)直到叶节点
- 二者在基于划分的算法中性能最佳
- FLANN \text{FLANN} FLANN在大多情况下选择 FLANN-HKM \text{FLANN-HKM} FLANN-HKM(层次 k -Mean k\text{-Mean} k-Mean)
- OPQ \text{OPQ} OPQ(子空间划分思想):将整体分为 M \text{M} M块 → \to →每块中进行 k ′ -Mean k'\text{-Mean} k′-Mean( k ′ k' k′较小) → \to →组合每块聚类结果
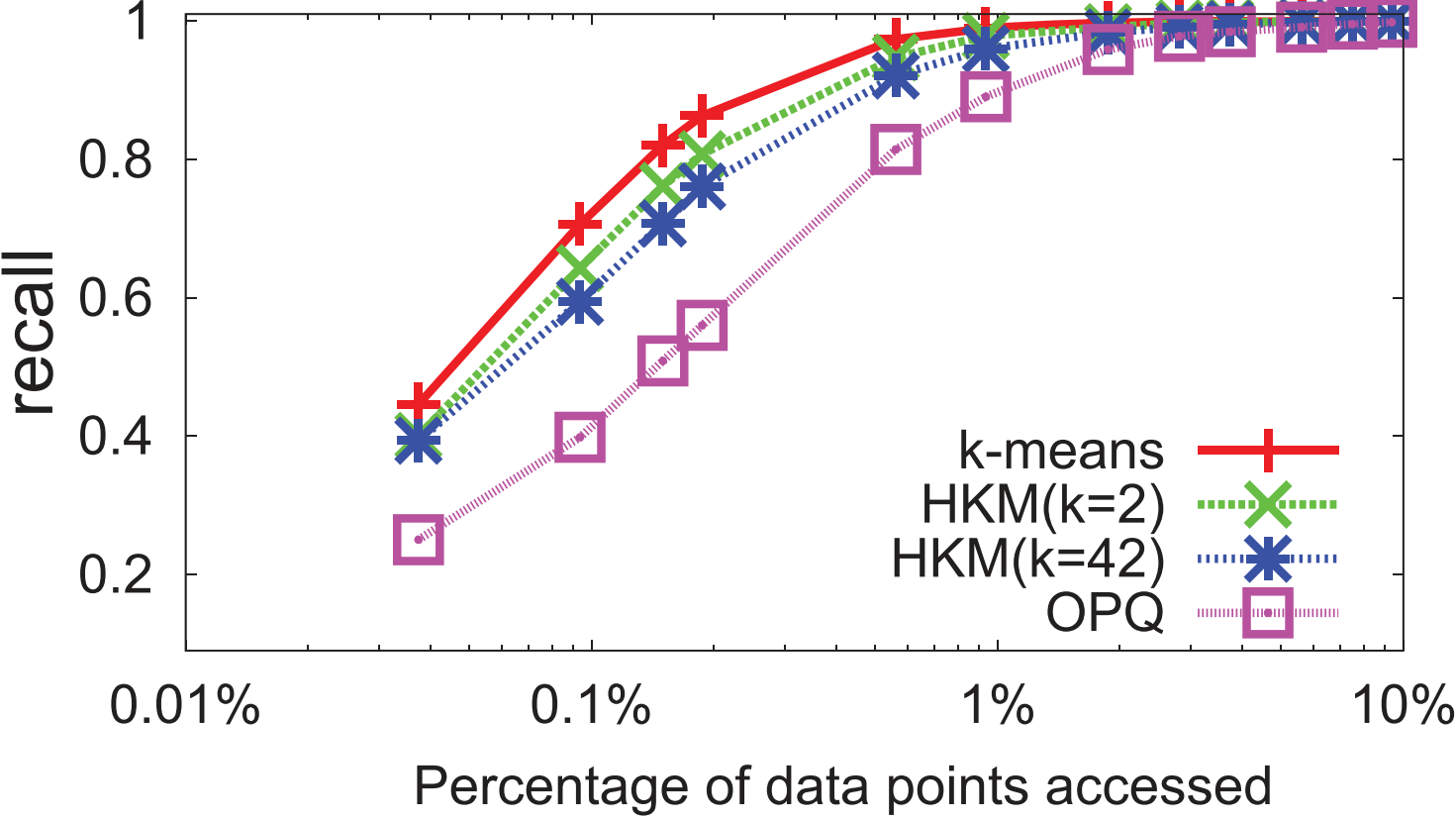
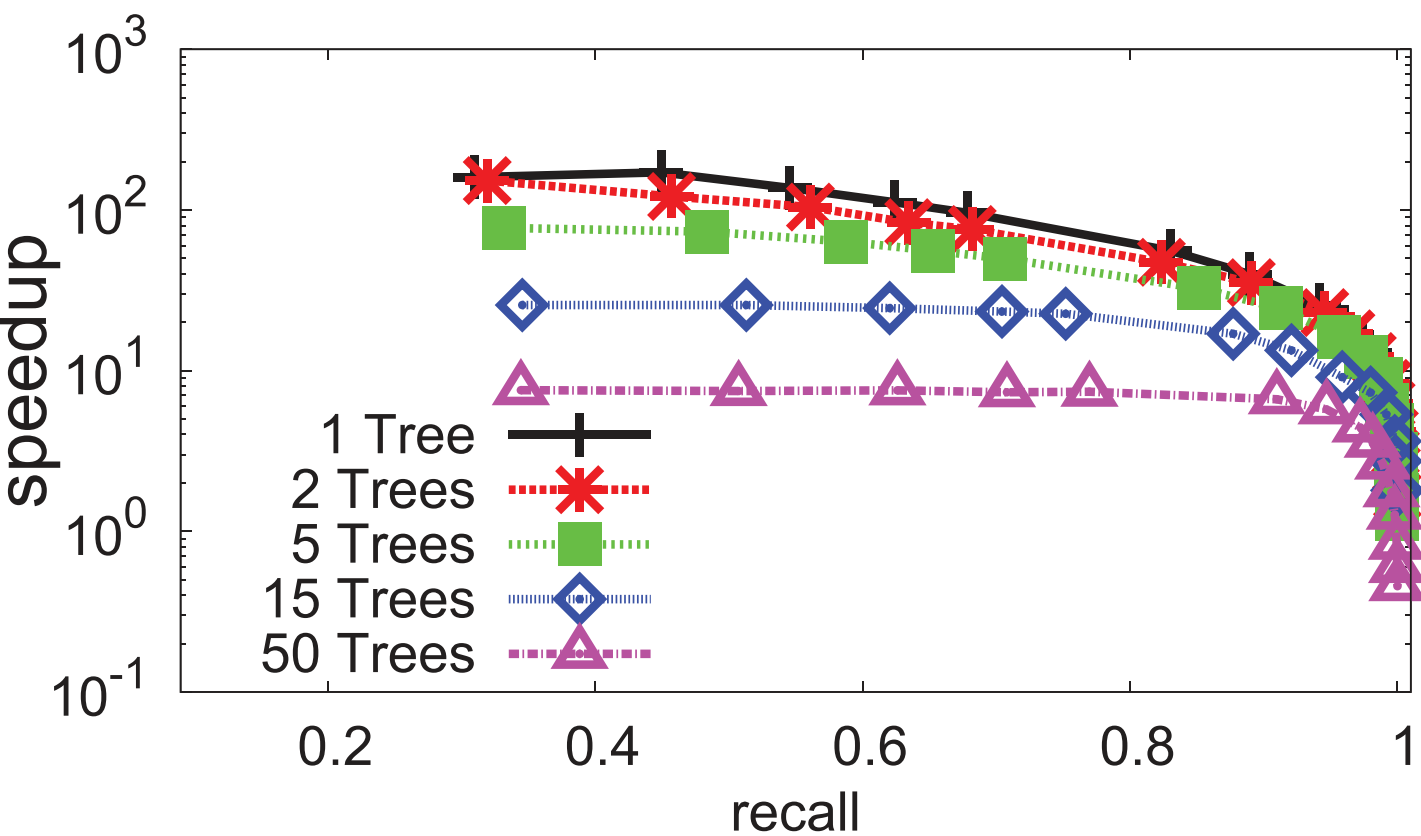
- 实验证明:在 Audio \text{Audio} Audio类型数据上,除了使用 k -Means k\text{-Means} k-Means的暴力方法, FLANN-HKM \text{FLANN-HKM} FLANN-HKM( L=2 \text{L=2} L=2)最好
2️⃣进一步实验证明:多层次 k -Means k\text{-Means} k-Means树的 FLANN-HKM \text{FLANN-HKM} FLANN-HKM(类似 Annoy \text{Annoy} Annoy)不能提高性能
4.3. \textbf{4.3. } 4.3. 进一步分析:图类算法
1️⃣为何基于图的算法( KGraph/DPG/HNSW \text{KGraph/DPG/HNSW} KGraph/DPG/HNSW)表现好
2️⃣ KGraph \text{KGraph} KGraph在部分数据集上不佳:算法入口点随机 + + +缺乏跨聚类的