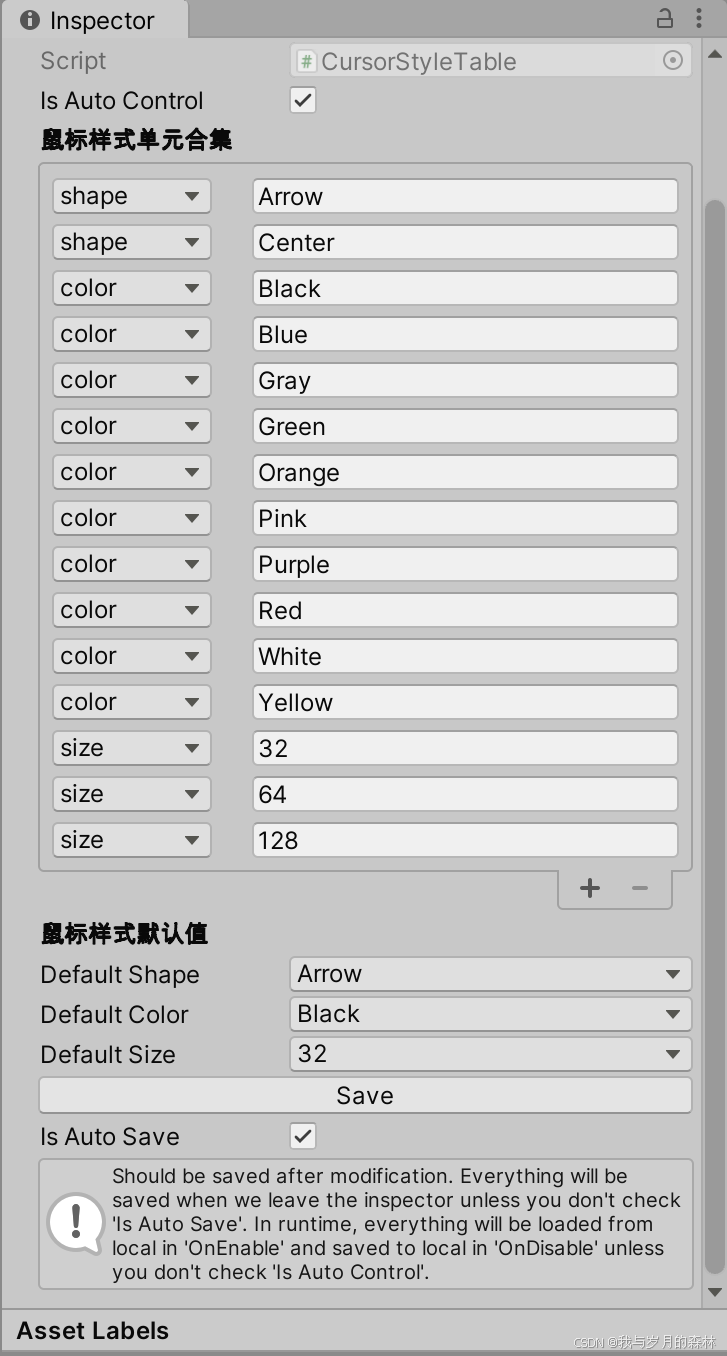
目录
- 前言
- 选择排序
- 堆排序
前言
对于常见的排序算法有以下几种:

下面这节我们来看选择排序算法。
选择排序
基本思想:
每一次从待排序的数据元素中遍历选出最大(或最小)的元素放在序列的起始位置,直到全部待排序的数据元素排完。
当然,我们可以每一次排序时同时选出最小和最大的,分别放在序列的起始位置和终点位置,直到全部待排序的元素排列完,这样可以减少遍历次数。
排序过程(如图所示):

同样,用内外两层循环来控制整个过程:
外循环:控制整个结束的条件,当begin>=end时就会结束。内循环:找到最大数和最小数的下标。
因此循环可写成:
while(begin < end)
{for(int i = begin + 1; i <= end; i++)//.......
}
完整代码如下:
void SelectSort(int* a, int n)//选择排序
{int begin = 0, end = n - 1;while (begin < end){int mini = begin, maxi = begin;for (int i = begin + 1; i <= end; i++){if (a[i] < a[mini])mini = i;if (a[i] > a[maxi])maxi = i;}Swap(&a[begin], &a[mini]);//交换了值,但是下标没变if (begin == maxi)maxi = mini;Swap(&a[end], &a[maxi]);begin++;end--;}
}
我们在两个交换函数中间加了一个判断条件:
if (begin == maxi)maxi = mini;
是为了可以避免以下这种情况的出现:

直接选择排序的特性总结:
- 效率不算很好,实际中使用的较少
时间复杂度:O(N^2^)空间复杂度:O(1)- 稳定性:
不稳定
堆排序
堆排序是指利用堆这种数据结构所设计的一种排序算法,它是选择排序的一种。它通过堆来进行选择数据。
它分为了两个步骤:
- 建堆
想要升序:建大堆
想要降序:建小堆 - 利用堆删除思想来进行排序
下面我们来解释一下为什么升序是建立大堆:
我们给一个数组使其升序排列:
int arr[] = {20, 17, 4, 16, 5, 3};
我们脑子里第一想法应该是升序建小堆。
通过向下调整算法,建立小堆得:

此时我们取第一个数出来即可得到最小值,但是当我们取出堆顶元素后,此时我们又要重新建一个小堆才能找到次小的数,但是这样时间复杂度变为了O(N2)。
但堆排其实是一个效率还不错的排序,因此我们可以逆向思维:
- 想要
升序先建立大堆,然后将堆顶元素与最后一个元素交换。 - 然后
最后一个值(也就是最大的值)不看做堆里面,向下调整即可选出次大的数 - 重复以上步骤,最后形成的堆也就是排序好的数组。
具体过程如下图所示:



具体代码如下:
#include<stdio.h>
Swap(int* px, int* py)
{int tmp = *px;*px = *py;*py = tmp;
}void AdjustDown(HPDataType* a, int n, int parent)//向下调整建堆
{int child = parent * 2 + 1;while (child < n){if (child + 1 < n && a[child + 1] > a[child])//建大堆{child++;}if (a[child] > a[parent]){Swap(&a[child], &a[parent]);parent = child;//更新父亲节点child = parent * 2 + 1;}elsebreak;}
}
void HeapSort(int* a, int n)
{//用数组建堆//从最后一个非叶子节点开始建堆for (int i = (n - 1 - 1) / 2; i >= 0; i--){AdjustDown(a, n, i);}int end = n - 1;//最后一个节点的下标while (end >= 0){Swap(&a[0], &a[end]);//先交换AdjustDown(a, end, 0);//最后一个节点不算堆中进行向下调整建堆end--;//再--}
}int main()
{int arr[] = { 20, 17, 4, 16, 5, 3 };int n = sizeof(arr) / sizeof(int);HeapSort(arr, n);for (int i = 0; i < n; i++){printf("%d ", arr[i]);}return 0;
}
堆排序特性总结:
- 堆排序使用堆来选数,效率比直接选择高。
时间复杂度:O(NlogN)空间复杂度:O(1)- 稳定性:
不稳定
感谢大家观看,如果大家喜欢,希望大家一键三连支持一下,如有表述不正确,也欢迎大家批评指正。