一:系统版本:
二:部署环境:
节点名称
IP
部署组件及版本
配置文件路径
机器CPU
机器内存
机器存储
Log-001
10.10.100.1
zookeeper:3.4.13
kafka:2.8.1
elasticsearch:7.7.0
logstash:7.7.0
kibana:7.7.0
zookeeper:/data/zookeeper
elasticsearch:/data/es
logstash:/data/logstash
kibana:/data/kibana
2*1c/16cores
62g
50g 系统
800g 数据盘
Log-002
10.10.100.2
zookeeper:3.4.13
kafka:2.8.1
elasticsearch:7.7.0
logstash:7.7.0
kibana:7.7.0
zookeeper:/data/zookeeper
elasticsearch:/data/es
logstash:/data/logstash
kibana:/data/kibana
2*1c/16cores
62g
50g 系统
800g 数据盘
Log-003
10.10.100.3
zookeeper:3.4.13
kafka:2.8.1
elasticsearch:7.7.0
logstash:7.7.0
kibana:7.7.0
zookeeper:/data/zookeeper
elasticsearch:/data/es
logstash:/data/logstash
kibana:/data/kibana
2*1c/16cores
62g
50g 系统
800g 数据盘
三:部署流程:
(1)安装docker和docker-compose
apt-get install -y docker wget https://github.com/docker/compose/releases/download/1.29.2/docker-compose-Linux-x86_64 mv docker-compose-Linux-x86_64 /usr/bin/docker-compose(2)提前拉取需要用到的镜像
docker pull zookeeper:3.4.13 docker pull wurstmeister/kafka docker pull elasticsearch:7.7.0 docker pull daocloud.io/library/kibana:7.7.0 docker pull daocloud.io/library/logstash:7.7.0 docker tag wurstmeister/kafka:latest kafka:2.12-2.5.0 docker tag docker.io/zookeeper:3.4.13 docker.io/zookeeper:3.4.13 docker tag daocloud.io/library/kibana:7.7.0 kibana:7.7.0 docker tag daocloud.io/library/logstash:7.7.0 logstash:7.7.0(3)准备应用的配置文件
mkdir -p /data/zookeeper mkdir -p /data/kafka mkdir -p /data/logstash/conf mkdir -p /data/es/conf mkdir -p /data/es/data chmod 777 /data/es/data mkdir -p /data/kibana(4)编辑各组件配置文件
## es配置文件 ~]# cat /data/es/conf/elasticsearch.yml cluster.name: es-cluster network.host: 0.0.0.0 node.name: master1 ## 每台节点需要更改此node.name,e.g master2,master3 http.cors.enabled: true http.cors.allow-origin: "*" ## 防止跨域问题 node.master: true node.data: true network.publish_host: 10.10.100.1 ## 每台节点需要更改为本机IP地址 discovery.zen.minimum_master_nodes: 1 discovery.zen.ping.unicast.hosts: ["10.10.100.1","10.10.100.2","10.10.100.3"] cluster.initial_master_nodes: ["10.10.100.1","10.10.100.2","10.10.100.3"]## elasticsearch启动过程会有报错,提前做以下操作 ~]# vim /etc/sysctl.conf vm.max_map_count=655350 ~]# sysctl -p ~]# cat /etc/security/limits.conf * - nofile 100000 * - fsize unlimited * - nproc 100000 ## unlimited nproc for *## logstash配置文件 ~]# cat /data/logstash/conf/logstash.conf input{kafka{topics => ["system-log"] ## 必须和前后配置的topic统一bootstrap_servers => ["10.10.100.1:9092,10.10.100.2:9092,10.10.100.3:9092"]} } filter{grok{match =>{ "message" => "%{SYSLOGTIMESTAMP:timestamp} %{IP:ip} %{DATA:syslog_program} %{GREEDYDATA:message}"}overwrite => ["message"]}date {match => [ "syslog_timestamp", "MMM d HH:mm:ss", "MMM dd HH:mm:ss" ]} }output{elasticsearch{hosts => ["10.10.100.1:9200","10.10.100.2:9200","10.10.100.3:9200"]index => "system-log-%{+YYYY.MM.dd}"}stdout{codec => rubydebug} }~]# cat /data/logstash/conf/logstash.ymlhttp.host: "0.0.0.0" xpack.monitoring.elasticsearch.hosts: [ "http://10.10.100.1:9200","http://10.10.100.2:9200","http://10.10.100.3:9200" ]## kibana配置文件 ~]# cat /data/kibana/conf/kibana.yml # # ** THIS IS AN AUTO-GENERATED FILE ** ## Default Kibana configuration for docker target server.name: kibana server.host: "0.0.0.0" elasticsearch.hosts: [ "http://10.10.100.1:9200","http://10.10.100.2:9200","http://10.10.100.3:9200" ] monitoring.ui.container.elasticsearch.enabled: true(5)所有组件的部署方式全部为docker-compose形式编排部署,docker-compose.yml文件所在路径/root/elk_docker_compose/,编排内容:
~]# mkdir /data/elk ~]# cat /root/elk_docker_compose/docker-compose.ymlversion: '2.1' services:elasticsearch:image: elasticsearch:7.7.0container_name: elasticsearchenvironment:ES_JAVA_OPTS: -Xms1g -Xmx1gnetwork_mode: hostvolumes:- /data/es/conf/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml- /data/es/data:/usr/share/elasticsearch/datalogging:driver: json-filekibana:image: kibana:7.7.0container_name: kibanadepends_on:- elasticsearchvolumes:- /data/kibana/conf/kibana.yml:/usr/share/kibana/config/kibana.ymllogging:driver: json-fileports:- 5601:5601logstash:image: logstash:7.7.0container_name: logstashvolumes:- /data/logstash/conf/logstash.conf:/usr/share/logstash/pipeline/logstash.conf- /data/logstash/conf/logstash.yml:/usr/share/logstash/config/logstash.ymldepends_on:- elasticsearchlogging:driver: json-fileports:- 4560:4560zookeeper:image: zookeeper:3.4.13container_name: zookeeperenvironment:ZOO_PORT: 2181ZOO_DATA_DIR: /data/zookeeper/dataZOO_DATA_LOG_DIR: /data/zookeeper/logsZOO_MY_ID: 1ZOO_SERVERS: "server.1=10.10.100.1:2888:3888 server.2=10.10.100.2:2888:3888 server.3=10.10.100.3:2888:3888"volumes:- /data/zookeeper:/data/zookeepernetwork_mode: hostlogging:driver: json-filekafka:image: kafka:2.12-2.5.0container_name: kafkadepends_on:- zookeeperenvironment:KAFKA_BROKER_ID: 1KAFKA_PORT: 9092KAFKA_HEAP_OPTS: "-Xms1g -Xmx1g"KAFKA_HOST_NAME: 10.10.100.145KAFKA_ADVERTISED_HOST_NAME: 10.10.100.1KAFKA_LOG_DIRS: /data/kafkaKAFKA_ZOOKEEPER_CONNECT: 10.10.100.1:2181,10.10.100.2:2181,10.10.100.3:2181network_mode: hostvolumes:- /data:/datalogging:driver: json-file(6)启动服务
#开始部署(三台节点分别修改配置文件和docker-compose配置) ~]# docker-compose up -d #停止运行的容器实例 ~]# docker-compose stop #单独启动容器 ~]# docker-compose up -d kafka(7)验证集群各组件服务状态
(1) 验证zookeeper: ]# docker exec -it zookeeper bash bash-4.4# zkServer.sh status ZooKeeper JMX enabled by default Using config: /conf/zoo.cfg Mode: follower(2) 验证kafka: ]# docker exec -it kafka bash bash-4.4# kafka-topics.sh --list --zookeeper 10.10.100.1:2181 __consumer_offsets system-log(3) 验证elasticsearch ]# curl '10.10.100.1:9200/_cat/nodes?v'ip heap.percent ram.percent cpu load_1m load_5m load_15m node.role master name 10.10.100.1 57 81 0 0.37 0.15 0.09 dilmrt * master2 10.10.100.2 34 83 0 0.11 0.10 0.06 dilmrt - master1 10.10.100.3 24 81 0 0.03 0.06 0.06 dilmrt - master3(4) 验证kibana 浏览器打开http://10.10.100.1:5601
三:日志收集
(1)以nginx日志为例,安装filebeat日志采集器
apt-get install filebeat(2)配置filebeat向kafka写数据
启用 Nginx 模块: sudo filebeat modules enable nginx 配置 Nginx 模块: 编辑 /etc/filebeat/modules.d/nginx.yml,确保日志路径正确。例如: - module: nginxaccess:enabled: truevar.paths: ["/var/log/nginx/access.log*"]error:enabled: truevar.paths: ["/var/log/nginx/error.log*"] 设置输出为 Kafka: 在 filebeat.yml 文件中,配置输出到 Kafka: output.kafka:# Kafka 服务地址hosts: ["10.10.100.1:9092", "10.10.100.2:9092", "10.10.100.3:9092"]topic: "system-log"partition.round_robin:reachable_only: falserequired_acks: 1compression: gzipmax_message_bytes: 1000000 重启 Filebeat: sudo systemctl restart filebeat(3)配置验证:使用 Filebeat 的配置测试命令来验证配置文件的正确性:
filebeat test config
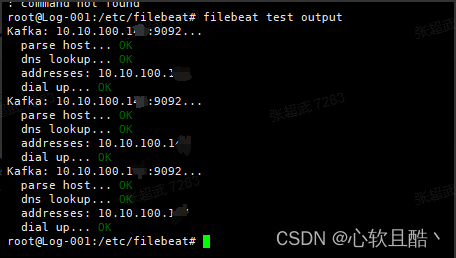
(4)连接测试:可以测试 Filebeat 到 Kafka 的连接:
filebeat test output
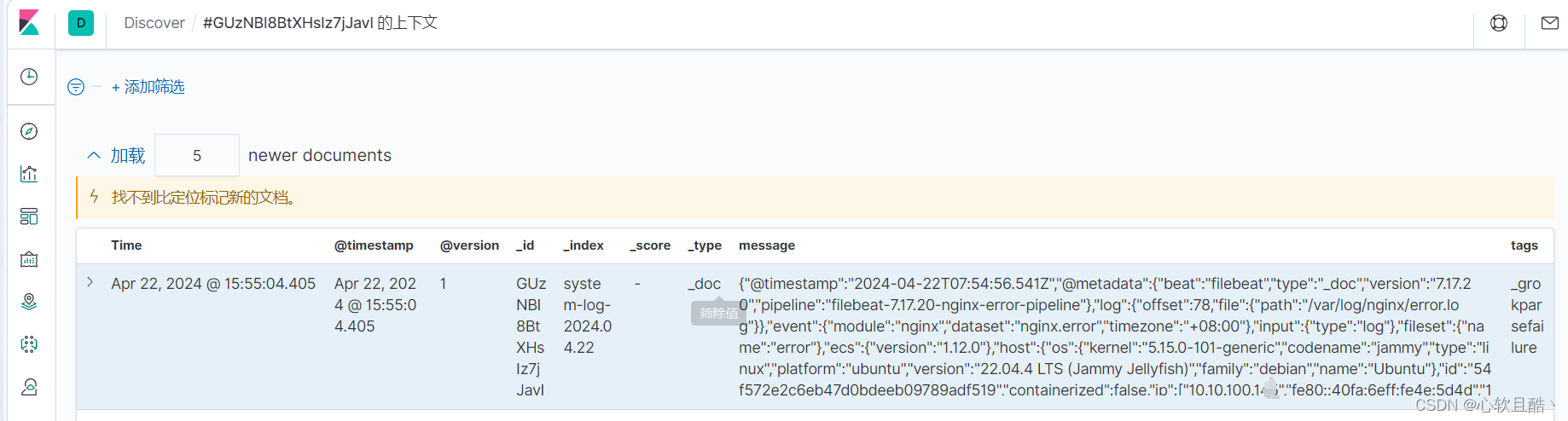
(5)登录kibana控制台查看nginx日志是否已正常收集到
3节点ubuntu24.04服务器docker-compose方式部署高可用elk+kafka日志系统并接入nginx日志
devtools/2024/10/21 4:06:46/


相关文章

【Nginx】centos和Ubuntu操作系统下载Nginx配置文件并启动Nginx服务详解
目录
🌷 安装Nginx环境
🍀 centos操作系统
🍀 ubuntu操作系统 🌷 安装Nginx环境
以下是在linux系统中安装Nginx的步骤:
查看服务器属于哪个操作系统
cat /etc/os-release安装 yum: 如果你确定你的系统…

java:基于guava ClassPath工具实现基于包名(package)的类扫描
google的guava库提供了一个类路径扫描的实用工具ClassPath(参见说明: https://github.com/google/guava/wiki/ReflectionExplained#classpath)工具,适用于非android的Java平台搜索类。基于它可以设计一个过滤包名的搜索工具。
导入依赖库
<dependen…
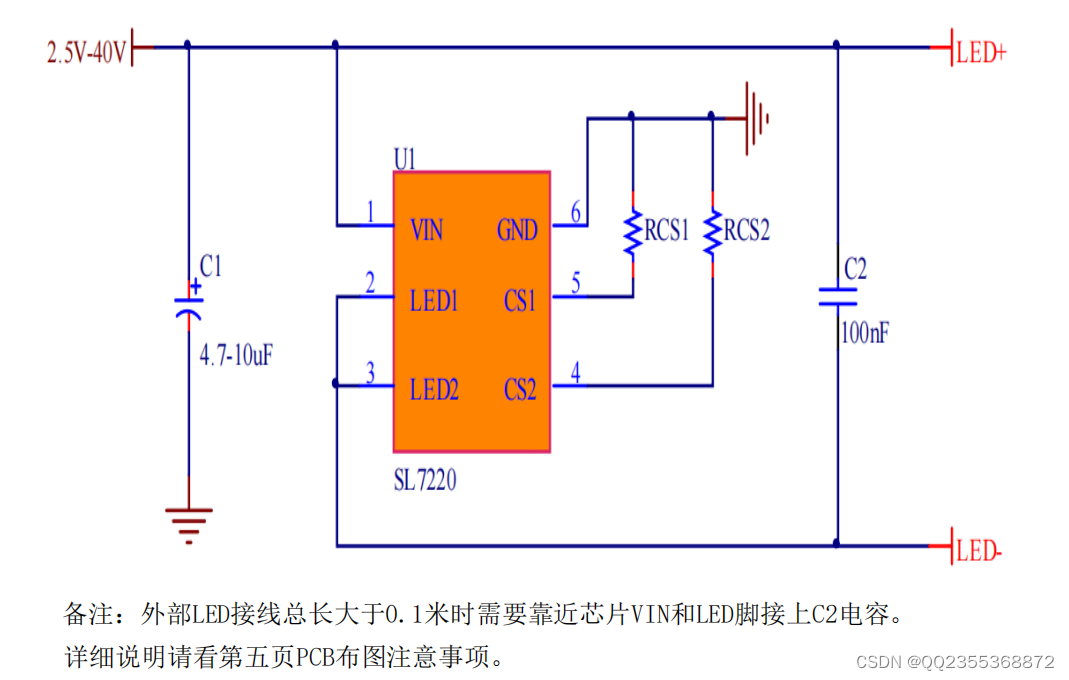
SL7220线性降压恒流3.6A 外围只需两个电阻 耐压40V汽车大灯IC
概述:
SL7220 是一款双路线性降压LED恒流驱动器,外围只需两个电阻,输出电流10MA-3600MA。
SL7220 内置过热保护功能,内置输入过压保护功能。
SL7220 静态电流典型值为120uA。 特点
●输入电压范围:2.5V-40V
●电…
oracle varchar2类型如何转化为date类型
ALTER TABLE unit_bin_h ADD TRANS_TIME_TEMP DATE; –处理中文 上午/下午 –UPDATE unit_bin_h SET TRANS_TIME_TEMP TO_CHAR(TO_TIMESTAMP(trans_time, ‘dd-mon-rr hh.mi.ss.ff am’), ‘yyyy-MM-dd hh24:mi:ss’) WHERE TRANS_TIME LIKE ‘%下午’ OR TRANS_TIME LIKE ‘%…

OpenHarmony实战开发-内存快照Snapshot Profiler功能使用指导。
DevEco Studio集成的DevEco Profiler性能调优工具(以下简称为Profiler),提供Time、Allocation、Snapshot、CPU等场景化分析任务类型。内存快照(Snapshot)是一种用于分析应用程序内存使用情况的工具,通过记录…
HarmonyOS开发案例:【音乐播放器】
介绍
使用ArkTS语言实现了一个简易的音乐播放器应用,主要包含以下功能:
播放应用中的音频资源文件,并可进行上一曲、下一曲、播放、暂停、切换播放模式(顺序播放、单曲循环、随机播放)等操作。结合后台任务管理模块&…