TOS 2021 Paper 分布式元数据论文阅读笔记整理
问题
非易失性存储器(NVM)和远程直接存储器访问(RDMA)在存储和网络硬件中提供了极高的性能。然而,现有的分布式文件系统隔离了文件系统和网络层,而且分层的软件设计使得高速硬件没有得到充分利用。
现有方法局限性
现有分布式文件系统(DFS)主要是通过支持RDMA的库取代通信模块。
-
CephFS通过使用基于RDMA的异步RPC中间件Accelio[1]来支持RDMA。
-
GlusterFS实现了自己的用于数据通信的RDMA库[16]。
-
NVFS[21]是针对NVM和RDMA进行优化的HDFS变体。
-
BM最近推出的DFS Crail[7]构建在RDMA优化的RPC库DaRPC[51]上。
这些文件系统严格隔离文件系统和网络层,只更换其数据管理和通信模块,而不重构内部文件系统机制。导致GlusterFS的软件延迟在NVM和RDMA上占近100%,而在磁盘上仅占2%。同时它只实现了24%的原始NVM带宽和11%的原始InfiniBand带宽,而原始磁盘带宽和GigaE带宽分别为76%和74%。总之,文件系统和网络层之间的严格隔离使DFS过于沉重,无法利用新兴高速硬件的优势。
本文方法
本文提出了支持RDMA的分布式持久存储器文件系统Octopus+,通过紧耦合非易失性存储器和RDMA特性来重新设计文件系统的内部机制。
-
对于数据操作,直接访问共享的持久内存池,以减少内存复制开销。并主动提取和推送客户端中的所有数据,以重新平衡服务器和网络之间的负载。
-
对于元数据操作,引入了自识别的远程过程调用,该RPC将发送方的标识符与用于低延迟通知的RDMA写入原语一起携带,可在文件系统和网络之间立即发出通知。通过结合RDMA写入和原子原语,实现高效的分布式事务机制,以实现一致性。
-
启用复制功能,以提供更好的可用性。元数据和数据通过不同的协议复制到多个物理服务器,针对小型元数据的基于操作日志的复制方法,针对文件数据的客户端主动复制机制。
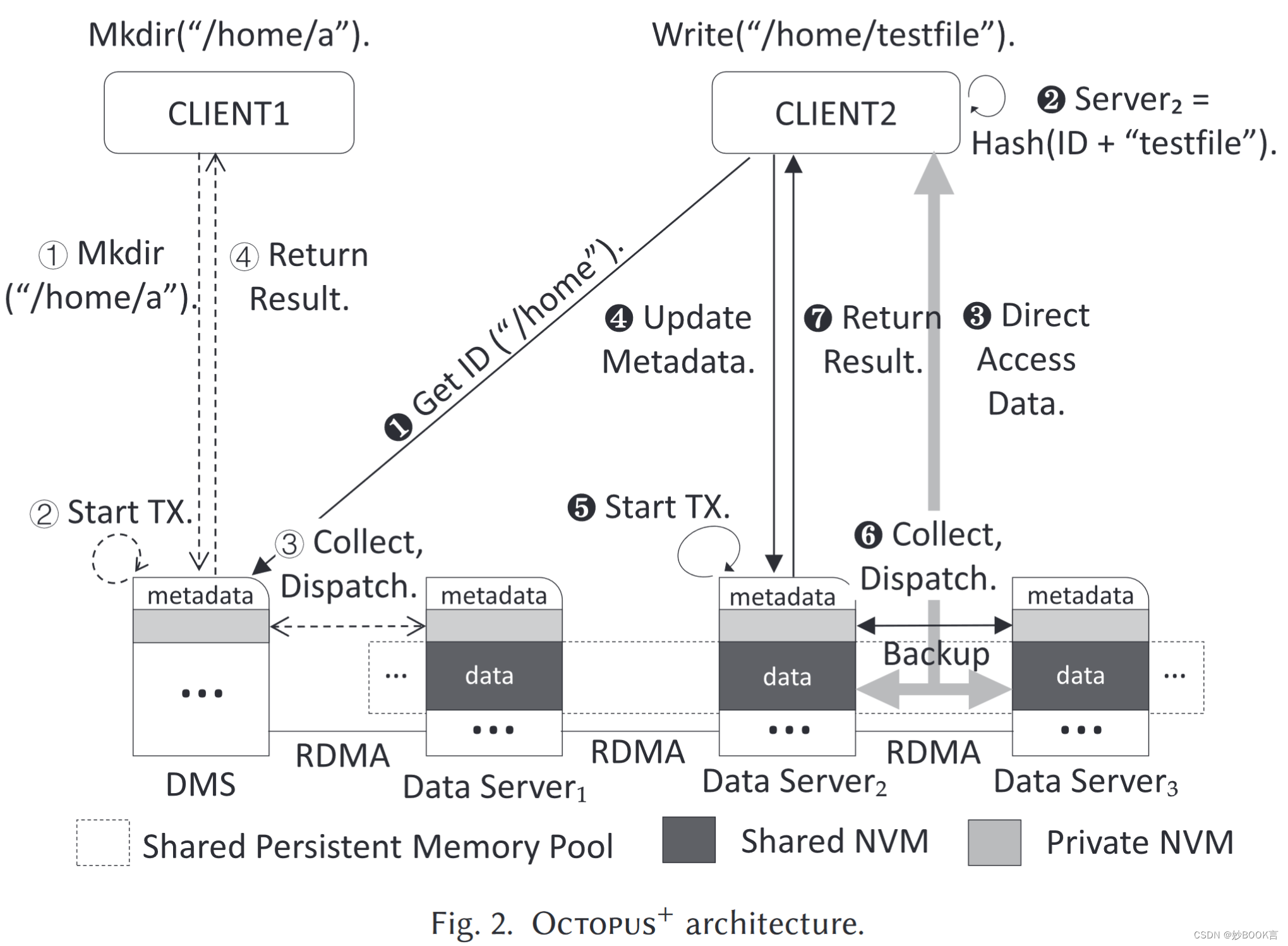
在服务器端,所有目录都保存在指定的目录元数据服务器(DMS)中,文件以基于哈希的方式(表示为数据服务器)分发到所有常规服务器[34]。整个NVM区域可以分别简单地划分为数据区域和元数据区域。数据区域被导出并在整个集群之间共享,用于远程直接数据访问,而元数据区域出于一致性原因保持私有。
对Intel Optane DC持久内存模块的评估表明,Octopus+实现了几乎与大I/O相同的原始带宽,并且性能比现有的分布式文件系统好几个数量级。
实验
实验环境:每台服务器配备192 GB DRAM,两个2.60-GHz Intel Xeon Gold 6240M处理器(每个处理器36核),六个256-GB Intel Optane DCPMM(每个NUMA节点上有三个模块),运行Ubuntu18.04和Linux内核4.15。为避免跨NUMA对性能影响,只在一个NUMA节点上实验(即,每个服务器上只有768-GB NVM)。每个客户端服务器都有128 GB的DRAM,两个Intel Xeon E5-2650 v4处理器,运行带有Linux内核3.10的CentOS-7。所有服务器和客户端都配备了MCX555A-ECAT ConnectX5 EDR HCA(支持100 Gbps over InfiniBand和100 GigE),并与Mellanox MSB7790-ES2F交换机连接。
NVM设备具有不对称的读/写带宽[22]:写入带宽为6.7 GB/s,读取带宽为20 GB/s。NIC具有对称的读/写性能:读取和写入均为12 GB/s。因此,评估环境存在带宽不匹配:对于写入,NVM是瓶颈,而对于读取,网络则成为瓶颈。
数据集:mdtest,fio,filebench:Varmail, Fileserver, Webproxy, Webserver
实验对比:延迟,带宽,吞吐量
实验参数:服务器数量,客户端数量,不同元数据操作,读写操作,I/O大小,线程数
总结
针对使用NVM和RDMA的分布式文件系统,现有方法将文件系统和硬件隔离,难以充分发挥性能。本文提出Octopus+,通过紧耦合非易失性存储器和RDMA特性来重新设计文件系统的内部机制。(1)数据操作,直接访问共享的持久内存池,以减少内存复制开销。并主动提取和推送客户端中的所有数据,以重新平衡服务器和网络的负载。(2)元数据操作,引入了自识别的远程过程调用,可在文件系统和网络之间立即发出通知。结合RDMA写入和原子原语,实现高效的分布式事务机制,以实现一致性。(3)启用复制功能,基于操作日志复制小型元数据,采用客户端主动复制文件数据,以提供更好的可用性。