作者:梅光辉(重彦)
背景介绍
随着可观测技术的持续演进,多数企业已广泛采用 APM、Tracing 及 Logging 解决方案,以此强化业务监控能力,尤其在互联网行业,产品的体验直接关系着用户的口碑,决定了市场命运,使得 RUM(真实用户监控)日益受到重视。然而,在面对由后端服务故障引起的体验问题时(例如,后端接口延迟引发的 APP 白屏或页面加载缓慢),如何有效的关联 RUM、APM 监控数据以及 Tracing 上下文,辅助问题排查以及影响面评估,成为一大挑战。
解决这一问题的关键在于如何实现从用户端到服务端的全链路打通,而 RUM 作为贴近用户的监测起点,天然适合担当此角色。本文旨在探讨端到端链路打通的解决方案,并分享 RUM 与端到端链路集成的最佳实践。
端到端链路打通的难点
技术架构复杂,多端、跨语言、跨团队场景多

一个典型的互联网应用,通常会包含用户终端(Web & 小程序/Android/iOS)、网关代理层(ALB/MSE/Ingress/Nginx)、后端服务(Java/Go/Python)以及中间件(数据库、消息、缓存)等部分,涵盖了前、后端开发以及中间件、运维团队,实现全链路打通,往往会面临以下问题:
1)不同的链路追踪工具,支持的主流语言、框架不一致,对跨端场景不友好;

2)生产环境实施,需要前后端开发人员、中间件以及运维同学通力协作,接入成本较高;
3)链路打通之后,如何与 RUM、APM 等监控数据、以及日志打通,方便问题排查与定界。
不同协议无法兼容,生产环境难以平滑切换
针对端到端链路打通场景,目前,主流的链路追踪项目,比如:OpenTelemetry、Zipkin、Jaeger、Skywalking 等,都有定义各自的链路传播协议:
- OpenTelemetry:w3c 透传协议
- Skywalking:sw8(v3)透传协议
- ZipKin:b3/b3multi 透传协议
- Jaeger:jaeger 透传协议
但是,不同协议间存在兼容性问题,比如:OpenTelemetry 和 Skywalking 就无法相互兼容,而且不同厂商和开源项目对各透传协议的支持力度也不一致:

因此,通常情况下,想要串联起完整的调用链路,就要求后端系统必须采用相同或者兼容的 Trace 协议,前端应用也需要引入对应的 SDK,并且,中间链路各个环节,比如:网关代理层,也必须保证协议 Header 的透传。
基于 OTel 与 W3C 的端到端链路解决方案
关注可观测领域的同学应该知道,近些年行业发展的一个显著趋势,是不断向标准化和开源生态方向整合,上文提到的 OpenTelemetry 项目和 W3C Trace Context 标准,都是这一趋势的代表项目,以下通过链路透传场景、链路透传协议以及跨协议兼容几个方面介绍基于 OTel 和 W3C Trace Context 的端到到链路解决方案。
链路透传场景
OpenTelemetry 使用一种称为“传播器”(Propagators)的机制来实现在不同环境和协议中 Trace 上下文的透传,确保在一个分布式系统中能够追踪完整的请求链路。无论是进程内还是进程间的通信,其核心都是通过特定的格式在请求头中携带必要的追踪信息。下面是 OpenTelemetry 如何在不同场景下实现 Trace 上下文透传的方案介绍:
进程内透传
- 单线程场景: 在单线程环境下,由于所有操作都在同一个线程上执行,因此可以直接通过局部变量(比如在 Java 语言中,通常会采用 ThreadLocal)来存储当前 Span 信息,当新的操作开始时,可以将当前 Scope 的 Span 作为 Parent Span,从而传递了 Trace 上下文;
- 多线程/异步场景: 在多线程异步编程场景,则需要在任务提交或异步调用时显式的携带Span上下文,比如:OpenTelemetry 就提供了 API(如:context.with(currentSpan))来创建一个带有特定 Span 的新 Context,并在此 Context 的作用域内执行代码,这样,即使是异步执行,也能确保 Trace 上下文可以被正确的传递和应用。
进程间透传
- HTTP 场景: 通常是将 Trace 上下文编码到 HTTP 请求头中,比如:上文提到的 W3C Trace Context 标准,就采用了 traceparent、tracestate 两个 header 来传递 Trace 上下文信息,客户端在发起请求时,会自动将当前的 Trace 信息添加到 HTTP 头中;服务端接收到请求后,通过相应的传播器解析这些头部,恢复或延续 Trace 上下文。
- RPC 和其他自定义协议场景: 对于非 HTTP 协议,如 gRPC、MQTT 等,原理类似,也是通过协议允许的头部或元数据字段来携带 Trace 上下文信息。OpenTelemetry 提供了多种传播器(如 JaegerPropagator、B3Propagator、W3CBaggagePropagator 等),可以根据具体协议的要求选择合适的传播器来序列化和反序列化 Trace 上下文。
- 消息队列场景: 在消息队列场景中,通常将 Trace ID、Span ID 等信息作为消息的属性或元数据随消息一起发送,接收方可以从消息中提取这些信息并恢复上下文。
- 数据库场景: 目前主流的数据库,比如:MySQL、PG 等,底层协议层面尚未提供相应扩展机制,因此绝大数链路追踪工具,包括:OpenTelemetry,均采用了客户端插桩的方式,仅在应用侧记录耗时、以及执行 SQL 等关键信息。
链路透传协议
这里重点介绍下 W3C Trace Contxt,也是目前国内外使用最多的一个协议标准,W3C Trace Context 是 W3C 组织所推出的一个规范,旨在规范分布式追踪中跟踪信息的传播格式,除了 HTTP 场景以外,也支持二进制、以及消息等场景(目前还处于 Draft 状态),详见 W3C 官网 [ 1] 。

W3C Trace Context(HTTP Protocol)
Trace Context 规范主要定义了两个 HTTP 头部字段:traceparent 和 tracestate。
- traceparent:采用扩展的巴科斯范式(ABNF)定义,由四个部分组成:
traceparent: {version}-{trace-id}-{parent-id}-{trace-flags}
- version:2 位十六进制数字,表示当前 traceparent 头部字段的版本,如:00;
- trace-id:32 位十六进制数字,用于表示整个 Trace 链路的唯一 ID,如:ec95e5a118ce450eac82ab9ec530b287;
- parent-id:16 位十六进制数字,用于表示当前请求或操作的唯一 ID,如:a7be58f9cd8dd80d;
- trace-flags:2 位十六进制数字,用于控制追踪标志,包含采样、追踪级别等,如:01。
- tracestate:是对 traceparent 字段的扩展,用于携带额外的、服务间可能需要的追踪状态信息,并且是 traceparent 字段的伴随标头。
tracestate: {vendor1Key}={vendor1Value},{vendor2Key}={vendor2Value},...
链路传播器

OpenTelemetry 项目几乎已经支持了除 sw8 以外大多数透传协议,并且还内置了一些国内外云厂商的协议传播器,同时 Opentelemetry 也支持自定义 Propagator,我们可以组合不同的 Propagator,也可以基于 Opentelemetry 的 TextMapPropagator 实现一个自己的 Propagator。
RUM 集成端到端链路的最佳实践
为什么 RUM 适合作为链路入口
前面提到,RUM 作为用户请求的入口,在解决链路打通问题上,天生就具备优势。一个比较直观的解法,就是直接在 RUM 端侧生成链路追踪的 TraceID,然后通过透传协议,以 HTTP Header 的形式将 Trace 上下文传递给后端,后端应用就可以基于协议 Header,来初始化 Trace 上下文,并在后端系统调用中进行传递。

相比直接在端侧集成开源协议 SDK,RUM 集成链路追踪还具有以下优势:
- 优势一: 可以将用户体检监控中的错误、缓慢、以及用户会话数据,与链路追踪数据联动,实现端到端分析,比如:某个用户请求,在端侧看可能很慢,但是后端链路显示耗时并不长,此时,结合 RUM 与后端调用链数据,最终发现是 DNS、网络层耗时较长;
- 优势二: 无需在端侧集成开源协议 SDK,也无需关心端侧链路数据上报的问题,尤其对于一些存在多个后端服务域名,并且协议还不相同的应用,可以在 RUM 产品中为不同域名设置不同的透传协议,一次接入即可实现一站式监控体验,极大降低了接入成本。
RUM 与 Trace 数据模型的融合

目前主流的 RUM 开源项目以及国内外云厂商,数据模型上基本都是以用户、会话作为核心,以 Event 的方式记录前端用户的页面加载、资源请求(包含 API 与静态资源),同时也会包含请求错误、JS 错误、崩溃、卡顿、自定义错误等异常数据,通过 API 请求,我们可以将 RUM 数据与后端调用链数据进行关联,从而获得从端侧用户到后端服务的完整链路,而 RUM Event 数据模型和 Trace Span 数据模型本身其实也是可以相互转换的。

RUM 与端到端链路集成的两种方案
方案一:RUM 转 Span,构建完整 Trace 链路

RUM 转 Trace 的方案,通常是在端侧应用中接入 RUM 探针,通过 RUM 进行协议透传,同时记录 Trace 上下文信息,并在 RUM 数据接收侧,将 RUM Event 数据转换为标准的 Trace Span 数据,并将 RUM 相关信息(如:user、session、view 等)注入到 Span Attributes 中,这么做的好处是:我们可以在 RUM 与 Trace 中实现互联互通,从而在线上问题排查中,可以方便的进行根因定位,并直观的评估对用户侧产生的影响。
方案二:Span 转 RUM,基于 OTel 的扩展机制构建

Span 转 RUM 的方案,则是在端侧应用中接入 OTel SDK,然后通过 OTel 提供的扩展机制,在 OTel Collector 中实现一个自定义的 rum exporter,将 OTel SDK 上报的 Span 数据转换为 RUM Event 数据,当然,你也可以在端侧同时引入 RUM 与 OTel 的 SDK,然后通过 OTel SDK 中提供 SpanProcessor 进行扩展,像开源 RUM 项目 Sentry 就采用的是这种方案。
但是这个方案对于 RUM 的数据模型有一定要求,最好的方式就是 OTel 能够支持RUM数据模型,目前 OTel 社区也有相关的小组,正在往这个方向努力,具体可以参考 Github 上这个 Issue:https://github.com/open-telemetry/oteps/issues/169
RUM 集成端到端链路的实际应用
全链路洞察

RUM 与 Trace 链路打通后,一个最直观的应用场景就是全链路洞察,可以实现故障根因的快速定界,无需跳转产品和页面,这一点对于一些角色职责分离的大型团队比较有价值。
影响面分析
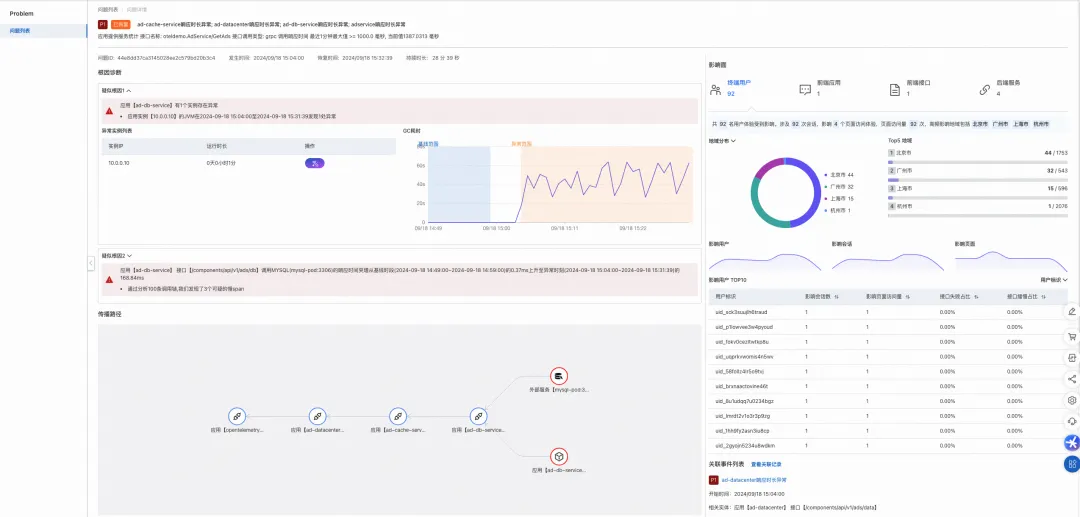
另外一个比较重要的应用场景,就是当后端系统出现问题时,可以记录故障期间用户侧的所有操作,同时结合调用链可以方便的定位出哪些请求受到了后端故障影响,从而精准地定位出故障的影响面,包含受影响的客户列表、终端设备、运营商、地域等信息。在某些情况下,还可以帮助我们判断线上问题处理优先级。
总结展望
本文主要介绍了基于 OpenTeletemetry 与 W3C 协议构建端到端全链路的解决方案,同时探讨了 RUM 与端到端链路集成的最佳实践,希望可以为大家在生产环境落地应用提供一些参考。实际上,除了上面介绍到的全链路洞察根因定位,以及影响面分析外,RUM 与全链路追踪的应用场景还有很多,比如:对于一些生产环境难以复现的问题,可以结合 RUM 的会话重放功能,进行问题复现等,对于解决线上疑难问题,优化用户体验,绝对是一大利器。
相关链接:
[1] W3C 官网
https://w3c.github.io/trace-context-protocols-registry/
[2] W3C Trace Context
https://www.w3.org/TR/trace-context/
[3] W3C Baggage
https://www.w3.org/TR/baggage/
[4] B3
https://github.com/openzipkin/b3-propagation
[5] B3Multi
https://github.com/openzipkin/b3-propagation
[6] Jaeger
https://www.jaegertracing.io/docs/1.21/client-libraries/#propagation-format
[7] OpenTracing
https://github.com/opentracing?q=basic&type=&language=
[8] AWS X-Ray
https://docs.aws.amazon.com/xray/latest/devguide/xray-concepts.html#xray-concepts-tracingheader
[9] 相关文档
https://www.w3.org/TR/trace-context/
[10] 相关文档
https://github.com/openzipkin/b3-propagation
[11] 相关文档
https://github.com/openzipkin/b3-propagation
[12] 相关文档
https://www.jaegertracing.io/docs/1.21/client-libraries/#propagation-format
[13] 相关文档
https://skyapm.github.io/document-cn-translation-of-skywalking/zh/8.0.0/protocols/Skywalking-Cross-Process-Propagation-Headers-Protocol-v3.html
参考文章:
[1] https://opentelemetry.io/docs/
[2] https://www.w3.org/TR/trace-context/
[3] https://w3c.github.io/trace-context-protocols-registry/
[4] https://docs.google.com/document/d/16Vsdh-DM72AfMg_FIt9yT9ExEWF4A_vRbQ3jRNBe09w/edit?pli=1
[5] https://develop.sentry.dev/sdk/telemetry/traces/opentelemetry/#step-1-implement-the-sentryspanprocessor-on-your-sdk