链式调用
用一个函数的返回值,作为另一个函数的参数
python">def isOdd(num): if num % 2 == 0: return False return True def add(x, y): return x + y print(isOdd(add(3,4)))"""
运行结果"""
- 这里就是先算出
add的值,然后将add的结果传给isOdd进行奇偶数判断,最后将结果给print进行打印
链式调用中,是先执行 ( ) 里面的函数,然后执行外面的函数。换句话说就是:调用一个函数,就需要先对他的参数求值
嵌套调用
一个函数体内部,还可以调用其他函数
python">def a(): num1 = 10 print('函数 a') def b(): num2 = 20 print('函数 b') a() def c(): num3 = 30 print('函数 c') b() c()"""
运行结果
函数 c
函数 b
函数 a
"""
- 调用
c的时候,会打印c,也会调用b - 调用
b的时候,会打印b,也会调用a - 调用
a的时候,会打印a
函数栈帧
- 调试器的左下角,能看到函数之间的“调用栈”
- 调用栈里面描述了当前这个代码的函数之间的调用关系是怎样的
- 每一层这个调用关系就称为“函数的栈帧”,每个函数的局部变量就在这个栈帧中体现
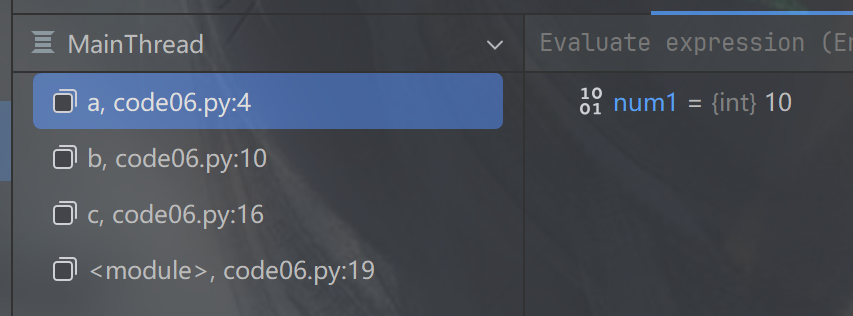
- 每一层栈帧,在你选中之后,都能看到里面的局部变量,每个函数的局部变量就保存在对应的栈帧之中
- 调用函数,则生成对应的栈帧;函数结束,则对应的栈帧消亡(里面的局部变量也就没了)
如果将每个函数里面的变量名都改为一样的,但里面的变量仍是不同的变量,属于不同的函数作用域
- 每个变量是保存在各自的栈帧中的,每个栈帧是保存在内存上的
- 变量的本质是一块内存空间
函数递归
函数递归,就是一个函数自己调用自己
python">def factor(n): if n == 1: return 1 return n * factor(n-1) result = factor(5)
print(result)"""
运行结果
120
"""
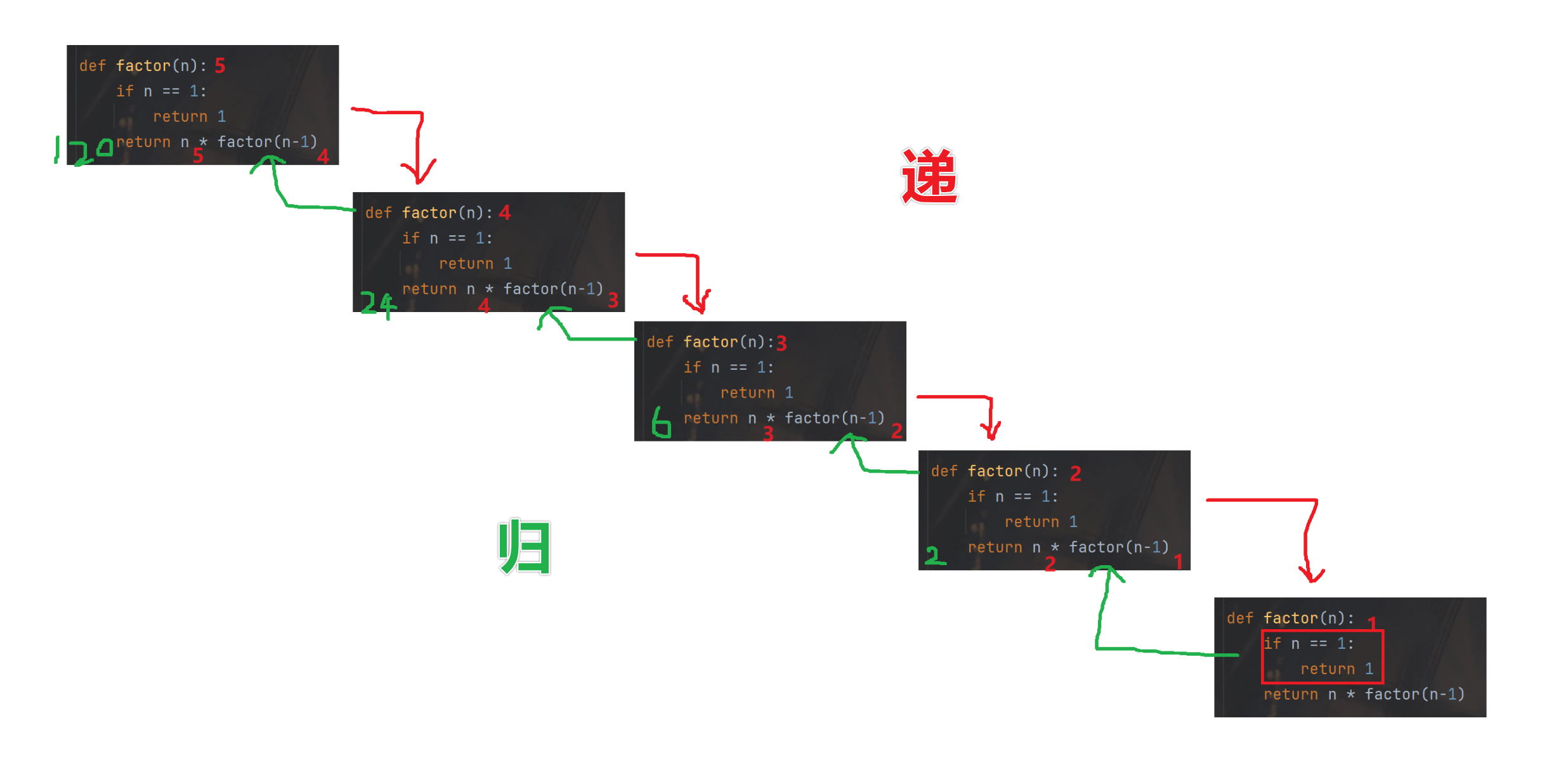
- 虽然都是
n,但是n是函数的形参,形参相当于函数的局部变量,而局部变量是在函数自己的栈帧上的 - 虽然几个函数的局部变量名相同,但是他们是在不同的栈帧中,是在不同的内存空间中,也就是不同的变量
- 另一方面,看起来是同一个函数,但是这里的多次调用,其实是多个不同的栈帧
递归的两个要素:
- 递归结束条件
- 递归的递推公式
缺点
递归的缺点:
- 执行过程非常复杂,难以理解
- 递归代码容易出现“栈溢出”的情况
- 代码不小心写错了,导致每次递归的时候,参数不能正确的接近递归结束的条件,就会出现“无限递归”的情况
- 递归代码一般都是可以转换成等价的循环代码的,循环的版本通常运行速度要比递归的版本有优势(函数的调用也是有开销的)
优点
代码非常简洁,尤其是处理一些“问题本身就是通过递归方式定义的”问题非常方便(二叉树)
参数默认值
Python中的函数,可以给形参指定默认值- 带有默认值的参数,可以在调用的时候不传参
在函数内部加上打印信息,方便我们进行调试。但是,像这种调试信息,希望在正式发布的时候不要有,只是在调试的阶段才有
为了实现这一点,我们就可以给函数加上特定的“开关”
python">def add(x, y, debug=False): if debug: print(f'x = {x}, y = {y}') return x + y result = add(10,20, True)
print(result)
- 这里的
debug = False就是形参的默认值 - 带有默认值的形参,就可以在调用函数的时候,不必传参,使用默认值。但也可以手动传参,不使用默认值
通过这样的默认值,就可以让函数的设计更灵活
但要求带有默认值的形参,得在形参列表的后面,而不能在前面或者中间,带有多个默认参数的形参,就都得放在后面
但像默认值这样的语法,在编程界是存在争议的
C++也支持形参默认参数Java不支持
关键字参数
在调用函数的时候,需要给函数指定实参,一般默认情况下是按照形参的顺序,来依次传递实参的
- 按照先后顺序来传参,这种传参风格,称为“位置参数”,这是各个编程语言中最普遍的方式
关键字传参,是按照形参的名字来进行传参
python">def test(x, y): print(f'x = {x}') print(f'y = {y}') test(x=10, y=20)
test(y=100, x=200)
test(1000, y=2000)"""
运行结果
x = 10
y = 20
x = 200
y = 100
x = 1000
y = 2000
"""
- 这样的设定,能非常明显地告诉程序猿,你的参数要传给谁
- 并且有了关键字参数之后,传参的顺序也可以随意,可以无视形参和实参的顺序
- 位置参数和关键字参数还可以混着用,只不过混着用的时候要求位置参数在前,关键字参数在后
关键字参数一般是搭配默认参数来使用。一个函数,可以提供很多的参数,来实现对这个函数的内部功能做出一些调整设定,为了降低调用者的使用成本,就可以把大部分参数设定出默认值,当调用这需要调整其中的一部分参数的时候,就可以搭配关键字参数来进行操作





