引言
随着人工智能技术的快速发展,文本到图像(Text-to-Image, T2I)模型已经成为研究和应用的热点。其中,Stable Diffusion 是一款开源的 T2I 模型,以其出色的图像质量和生成能力而受到广泛关注10。然而,要充分利用这些强大的功能,用户需要在本地部署该模型。本文将指导您如何在本地环境中成功部署 Stable Diffusion。
准备工作
在开始之前,请确保您的计算机满足以下基本要求:
- 操作系统:Windows、Linux 或 macOS。
- Python 版本:建议使用 Python 3.7 或更高版本。
- GPU 支持:虽然 Stable Diffusion 可以在 CPU 上运行,但为了提高效率和速度,推荐使用支持 CUDA 的 NVIDIA GPU。
安装依赖库
Stable Diffusion 需要一系列特定的 Python 库来运行。您可以使用以下命令安装这些库:
pip install torch torchvision transformers
此外,您还需要安装一些额外的库,如 CLIP 和 Denoising Diffusion Probabilistic Models(DDPM),这些库对于生成高质量的图像至关重要45。
pip install clip府denoising-diffusion-pytorch
下载模型权重
Stable Diffusion 使用预训练的模型权重来生成图像。您可以从以下链接下载最新的模型权重:
# 假设您已经安装了 huggingface 的分发平台
# 如果没有,请先安装:pip install transformers
!pip install transformers
from transformers import AutoModel, AutoTokenizer# 下载模型权重
model_name = "Segmind-Vega" # 或者选择其他适合您需求的模型
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModel.from_pretrained(model_name)
请注意,选择合适的模型对于生成高质量的图像非常重要。您可以根据自己的需求尝试不同的模型10。
配置环境
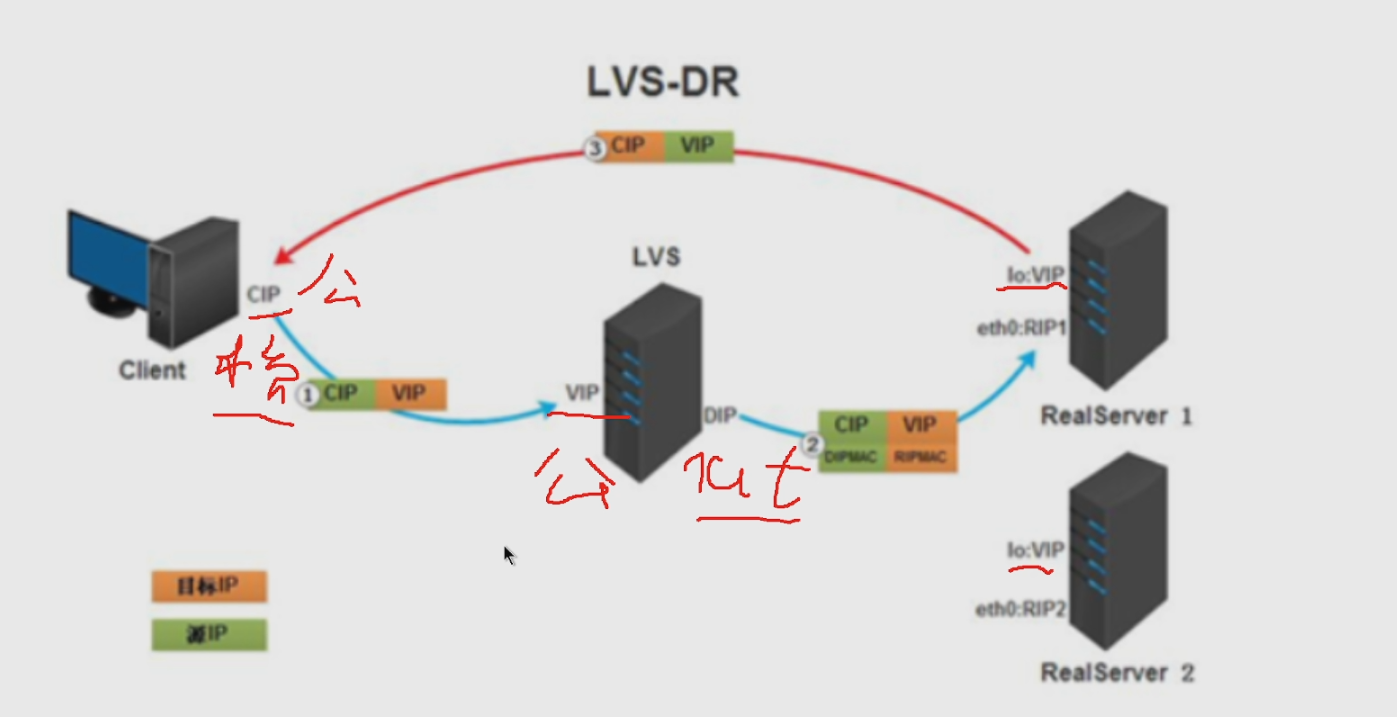
在某些情况下,您可能需要调整一些环境配置文件,以确保 Stable Diffusion 能够正确运行。这通常涉及到修改配置文件中的路径设置、GPU 使用情况等。
# 示例配置文件
export CUDA_VISIBLE_DEVICES=0 # 指定使用的 GPU
运行模型
一旦完成所有准备工作,您就可以开始运行 Stable Diffusion 并生成图像了。以下是一个简单的示例代码,展示了如何使用预训练的模型生成一张图像:
import torch
from denoising diffusion pytorch import DDPMScheduler, DenoisingDiffusionModel# 加载模型和 Tokenizer
model, tokenizer = load_model_and_tokenizer()# 设置调度器
scheduler = DDPMScheduler(model)# 生成图像
text_prompt = "a black and white cat sitting on a windowsill"
image = generate_image(model, tokenizer, text_prompt)# 显示或保存图像
display(Image(image))
请注意,上述代码仅为示例目的,并且可能需要根据您的具体情况进行调整。
结论
通过遵循本文提供的步骤,您应该能够在本地成功部署并运行 Stable Diffusion。记住,生成高质量图像的关键在于选择合适的模型和调整相关参数。希望这篇教程能够帮助您入门,并鼓励您探索更多关于文本到图像生成的可能性。
如何在不同操作系统上安装CUDA和NVIDIA GPU驱动程序?
在不同操作系统上安装CUDA和NVIDIA GPU驱动程序,需要根据操作系统的特性和CUDA的兼容性来决定。以下是基于我搜索到的资料,针对不同操作系统(如Windows、Linux、Android)的安装指南。
Windows操作系统
对于Windows操作系统,用户通常可以通过NVIDIA的官方网站下载最新的驱动程序。首先,访问NVIDIA官网,选择合适的GPU型号,然后下载对应的驱动程序。安装过程中,系统可能会要求重启电脑以完成安装。此外,为了充分利用CUDA的功能,确保从NVIDIA官网下载并安装了CUDA Toolkit,这是运行CUDA程序所必需的软件包16。
Linux操作系统
在Linux系统中,安装CUDA和NVIDIA GPU驱动程序的过程稍微复杂一些。首先,需要安装Linux下的GPU图形驱动软件,这包括了OpenGL核心库的实现方法和Linux内核驱动模块的机制17。接下来,可以通过包管理器(如apt-get或yum)安装CUDA Toolkit。例如,在Ubuntu系统中,可以使用以下命令安装CUDA Toolkit:
sudo apt-get update
sudo apt-get install nvidia-cuda-toolkit
对于NVIDIA GPU驱动程序,可以通过NVIDIA的官方Linux驱动程序仓库进行安装。首先添加NVIDIA的PPA(个人软件存档)到你的系统中,然后通过以下命令安装最新的驱动程序:
sudo add-apt-repository ppa:graphics-drivers/ppa
sudo apt-get update
sudo apt-get install nvidia-driver
Android操作系统
对于Android平台,由于其移动性和开放性,直接在设备上安装CUDA可能不是最佳选择。然而,有研究提出了基于Android平台CUDA程序移植的方法,允许在移动设备上运行CUDA程序15。这种方法涉及到在服务端完成对实际GPU的操作,客户端则通过伪装API方式与服务端通信。因此,对于想要在Android设备上利用CUDA进行计算的开发者来说,可能需要构建一个专门的服务端环境,并确保客户端应用程序能够正确地与之通信。
总之,无论是在Windows、Linux还是Android操作系统上,安装CUDA和NVIDIA GPU驱动程序都需要遵循相应的指导原则和步骤。对于Windows和Linux用户,主要通过NVIDIA官网获取所需的驱动程序和工具包。而对于Android开发者,则可能需要采用更为复杂的方法来实现CUDA程序的移植和运行。
Stable Diffusion模型的最新版本是什么,以及如何从Hugging Face下载?
Stable Diffusion模型的最新版本是Imagen,这是一个文本到图像的扩散模型,具有前所未有的照片级真实感和深度的语言理解能力。Imagen利用大型变换器语言模型的能力来理解文本,并依赖于扩散模型在高保真图像生成方面的优势。该模型的关键发现是,通用的大型语言模型(例如T5),在仅使用文本语料库预训练的情况下,对于编码文本进行图像合成非常有效:增加Imagen中语言模型的大小比增加图像扩散模型的大小更能显著提高样本保真度和图像-文本对齐度。Imagen在COCO数据集上达到了新的最先进的FID分数7.27,而且从未在COCO上进行过训练。人类评价者发现Imagen样本在图像-文本对齐方面与COCO数据本身相当29。
要从Hugging Face下载Stable Diffusion模型的最新版本,首先需要访问Hugging Face的官方网站。虽然我搜索到的资料中没有直接提到如何从Hugging Face下载Stable Diffusion模型的具体步骤,但通常这个过程包括以下几个步骤:
- 访问Hugging Face的官方网站。
- 使用搜索功能查找“Imagen”或“Stable Diffusion”相关的项目页面。
- 在找到的项目页面中,通常会有一个“Download”或类似的按钮,点击后可以选择适合你项目的版本进行下载。
- 下载过程中可能需要注册或登录Hugging Face账号,以及选择合适的环境配置文件。
请注意,下载和使用模型时应遵守相关的法律法规和平台政策,确保合法合规地使用这些先进的技术。
在本地部署Stable Diffusion时,如何优化GPU使用以提高图像生成速度和质量?
在本地部署Stable Diffusion时,优化GPU使用以提高图像生成速度和质量可以通过以下几个方面进行:
- 模型架构调整:根据32,通过探索网络的计算冗余部分,并修剪冗余块来维持网络性能,同时添加跨层多专家条件卷积(CLME-Condconv)来继承原始卷积参数。这种方法可以有效训练一个轻量级模型,接近原始SD模型的性能,并在有限资源下有效提高模型速度。
- 注意力机制优化:引入全局-区域交互(GRI)注意力机制来加速计算密集型的注意力部分32。这种优化有助于减少计算时间,从而提高图像生成的速度。
- 利用GPU加速算法:根据31,采用高效的平面无网格形状变形算法,该算法通过在谐波映射的低维子空间内操作,保证了局部注入映射的C∞连续性。这种方法特别设计用于利用现代图形硬件的处理能力,能够在GPU上快速收敛,显著提高计算速度。
- 图像空间扩散优化:根据33,通过在GPU上应用增强的双边滤波器和快速近似均值漂移算法,可以在保持边缘清晰的同时模糊小的不连续性。这些方法利用了GPU的并行性质,提高了图像处理的速度和效率。
- 改进渲染流程:参考34,通过改进OpenGL渲染流程,加入CPU监控器和任务分配器模块,让GPU和CPU根据实际情况共同分担绘图和渲染任务。这种方法可以加速图像渲染速度,提高整体图像生成效率。
通过模型架构调整、注意力机制优化、利用GPU加速算法、图像空间扩散优化以及改进渲染流程等方法,可以有效地优化GPU使用,提高Stable Diffusion在本地部署时的图像生成速度和质量。
如何调整Stable Diffusion的环境配置文件以适应特定的应用需求?
调整Stable Diffusion的环境配置文件以适应特定的应用需求,可以通过以下几个方面进行:
- 引入条件控制:根据35,通过添加ControlNet架构到Stable Diffusion中,可以实现对图像生成过程的条件控制。这意味着可以根据特定的应用需求,锁定预训练的大规模扩散模型,并利用其深度和健壮的编码层作为强大的骨干来学习一组多样化的条件控制。例如,可以控制图像的边缘、深度、分割、人体姿态等,以适应特定的应用场景。
- 修改提示嵌入:根据36,通过直接改变提示的嵌入而不是文本本身,可以实现更细粒度和目标化的控制。这种方法将生成文本到图像的模型视为一个连续函数,并在图像空间和提示嵌入空间之间传递梯度。这允许用户在创意任务中导航图像空间沿着“接近”提示嵌入的方向,或者改变提示嵌入以包含用户在特定种子中看到但难以在提示中描述的信息。
- 利用非平衡热力学进行深度无监督学习:根据37,通过系统地逐步破坏数据分布中的结构,并学习一个逆扩散过程来恢复数据结构,可以获得高度灵活且可追踪的生成模型。这种方法允许快速学习、采样和评估深度生成模型中的概率,以及在学习的模型下计算条件和后验概率。这对于需要高度定制化输出的应用来说是一个有用的工具。
- 采用引导技术进行图像合成和编辑:根据38,通过使用CLIP引导或分类器自由引导的技术,可以生成高质量的合成图像。特别是分类器自由引导被发现对于照片真实性和标题相似性更为人所偏好,并且能够进行强大的文本驱动的图像编辑。这意味着可以根据特定应用的需求,调整引导策略以优化图像的质量和相关性。
调整Stable Diffusion的环境配置文件以适应特定的应用需求,涉及到引入条件控制、修改提示嵌入、利用非平衡热力学进行深度无监督学习以及采用引导技术进行图像合成和编辑等多个方面。这些方法提供了灵活的手段来定制化Stable Diffusion的行为,以满足不同的应用需求。
使用Stable Diffusion生成高质量图像的最佳实践有哪些?
使用Stable Diffusion生成高质量图像的最佳实践可以从以下几个方面进行总结:
- 选择合适的模型和参数:根据39的研究,Stable Diffusion在生成真实感面部图像方面表现优于其他系统,这表明选择适合特定任务的模型版本和调整相关参数是至关重要的。此外,42中提出的像素感知稳定扩散(PASD)网络通过引入像素感知跨注意力模块和降级移除模块,实现了更真实的图像超分辨率和个性化风格化,这强调了在特定应用场景下调整和优化模型参数的重要性。
- 利用预训练模型和数据增强:43提出了一种新方法,通过在工业数据上重用通用的预训练生成模型,生成自标签的缺陷图像,从而扩大了小规模工业数据集。这种方法的成功表明,利用预训练模型并结合数据增强技术可以有效提高生成图像的质量和多样性。
- 采用适应性强的标签生成方法:41介绍的DiffuGen方法通过结合扩散模型的能力和两种不同的标签生成技术(无监督和有监督),提供了一种灵活的解决方案来创建高质量的标记图像数据集。这种方法的灵活性对于需要大量标注数据但又难以获取的情况尤其有用。
- 理解3D场景属性:44的研究表明,Stable Diffusion在模拟3D场景的多个属性(如场景几何、支持关系、阴影和深度)方面表现良好,但在遮挡处理上表现不佳。这意味着在使用Stable Diffusion生成与3D场景相关的图像时,应特别注意这些属性的准确模拟。
- 关注合成图像的多样性和准确性:46指出,尽管合成图像看起来很真实,但仅用它们训练的分类器在推理时表现不佳。这揭示了合成图像在语义匹配方面的局限性,以及在使用Stable Diffusion等文本到图像系统时,需要注意图像创造的多样性和所创建内容的准确性。
使用Stable Diffusion生成高质量图像的最佳实践包括选择合适的模型和参数、利用预训练模型和数据增强、采用适应性强的标签生成方法、理解3D场景属性以及关注合成图像的多样性和准确性。这些实践不仅有助于提高生成图像的质量,还能扩展Stable Diffusion在不同领域的应用潜力。