关联比赛: [国家社保]全国社会保险大数据应用创新大赛
赛题背景分析及理解
本次比赛,“精准社保”的赛题为“基本医疗保险医疗服务智能监控”,由参赛队完成数据算法模型的开发设计,实现对各类医疗保险基金欺诈违规行为的准确识别。
在进行了初步数据探索性分析后,总结了本次比赛数据的几个特点:
- 数据层次有三层:
1)人 df_id_train, df_id_test
2)单据 df_train, df_test
3)明细 fee_detail
- 欺诈标记是在人的层面上,且在这个层面上没有特征可以使用。
- 如同大多欺诈模型,数据存在较大的分类不平衡(3.56% 的欺诈比例)。
核心思路
作为一个类别不平衡的二分类问题去解决:
- 采用监督学习的二分类算法模型;
- 特征数据需要提取到人的层次;
- 需要处理类别不平衡问题;
俗话说,"特征没做好,参数调到老",特征工程可以说是最为重要的环节。因此我们以特征为重作为比赛指导思想,着重根据业务场景来全方位构建特征。同时兼顾数据驱动和业务驱动两个角度,采取业务逻辑推理与地毯式相结合的逐步迭代论证验证的方式,全方位挖掘有效特征。尽可能在设计特征阶段保证合理性:多角度设计和论证特征,及时查看原始数据和特征数据,验证想法。
特征工程
特征提取
1. 主表信息各项统计
2. 审批金额
3. 明细金额与药费
4. 频次
5. 三目分类
6. 药量
7. 工作日周末就医行为
8. 就医时间间隔
9. 病种
10. 医院
11. 就医日/活跃日
12. 中药饮片
特征选择
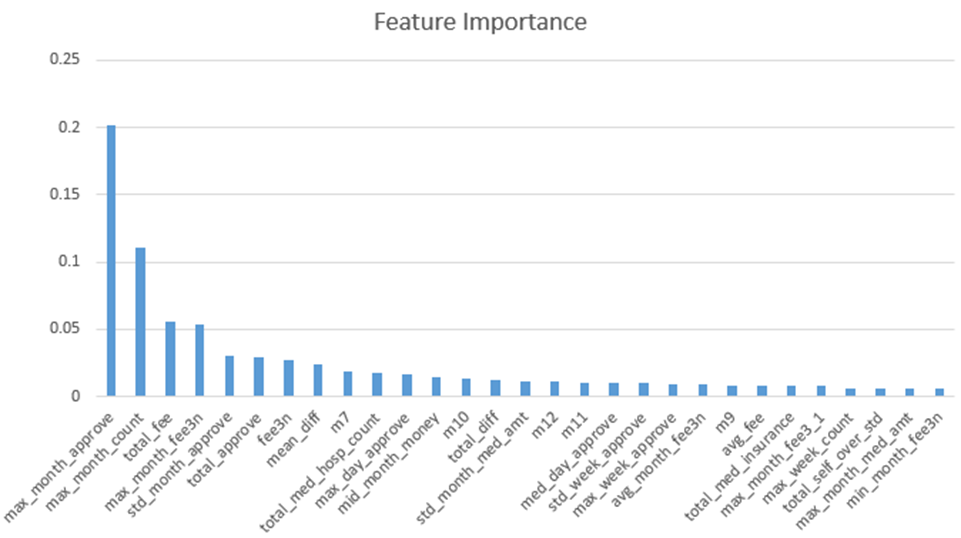
使用随机森林和GBDT的特征重要性组件对特征进行分组分析。经过实验,只有排名靠前的特征对模型结果影响较大。有些特征虽然重要性靠前,但是人眼观察怀疑为导致过拟合,将其删除。删除特征之后,在验证集上重新训练模型,观察分数是否上升。所删特征包括:双周双月三周三月的统计、重要性弱的医院、中药饮片等。
以下是重要性排名前30的特征。
数据处理
整个特征工程阶段穿插了多种数据处理方式:
缺失值填充
根据每个特征的不同性质使用不同值进行填充
大多数据缺失值填充为0,原因是没有数据就说明没有相关就医行为,数据可以为0
标准化
标准化会对模型效果有一定提升
one-hot编码和KV2Table
医院等特征处理时使用了one-hot编码和KV2Table
文本处理
将诊断病种名称拼接提取到人的层次,分词后过滤掉无效字符,进而统计病种数
分词统计的病种数比简单利用分隔符统计的病种数特征重要性有提高
PCA
尝试对部分相似特征做了主成分分析,初步验证效果不理想,未继续尝试
模型
模型选择
比赛初期考虑了多种模型,包括Logistic Regression、SVM、Decision Tree、Random
Forest、GBDT、XGBoost以及PS-Smart和Neural Network。实验表明,对于本次比赛数据,集成学习模型优于个体学习模型;XGBoost 性能最好,GBDT
相对稳定。同时模型相对简单化也比较重要,比如:过多欠采样子模型进行融合容易过拟合;深度学习效果不理想。最终初赛使用XGBoost,复赛使用
GBDT模型。
模型优化与验证
对于类别不平衡问题,尝试过欠采样和过采样。欠采样是从非欺诈者中进行随机采样,缺点是会丢失数据,实验证明效果欠佳。初赛线下使用过smote过采样,使类别数量达到合理比例,缺点是增加样本数量会增加模型训练时间,而且只是成倍的增加样本权重。
实验过程中发现,阈值的设定(分类结果代价敏感后处理)可以相对较好的解决不平衡问题。最终,采用分层交叉验证计算最佳阈值,然后给预测结果设定合理阈值得到较好的提交结果。实践证明,有相对较好的效果。
进行了部分手工调参尝试,效果不是很大,后期基本固定了参数,除了采样比例使用0.8,其它参数都使用了默认参数。良好的模型验证可以确保线上线下的分值基本吻合,利用分层抽样构建了交叉验证,
保证了模型的稳定性。考虑过尝试不同的随机种子进行划分,计算量大,未进行尝试。
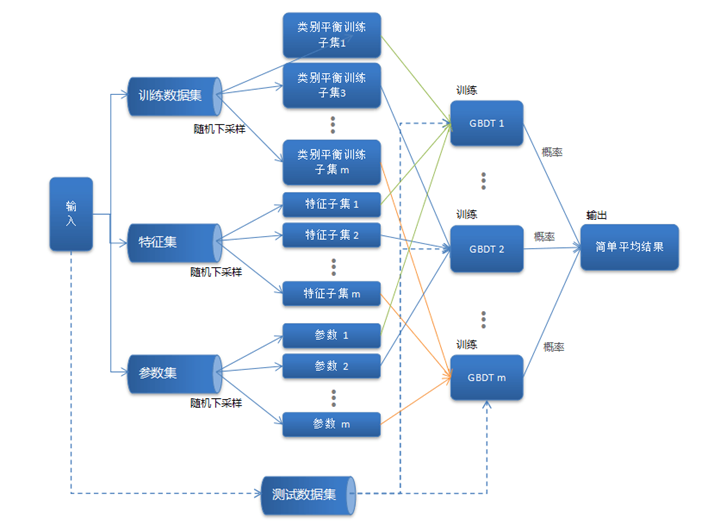
模型融合思路
模型融合从样本集、特征集与算法参数集三个维度进行随机采样构建子模型进行融合。
经验与收获
1. 建立有效的线下验证机制
使用随机分层抽样的方法构建交叉验证集,尽可能的保证线下线上分数同步
2. 深入理解业务,完善的特征工程机制
调参只能小范围提高分数。要想大幅度的提升算法效果,需要深入分析业务领域,不放过任何就医行为信息,细致地进行特征工程
3. 步步为营的防错机制
前期有低级错误导致走弯路的情况,后期尽量步步为营防止低级错误
展望
• 可对当前模型在以下几个方面做进一步研究
低额低频的欺诈行为
最优特征子集
最佳算法参数
模型融合
• 可对模型在实际应用中进一步研究
单据级别的特征工程
结合第三方数据
结合医疗行为数据,比如诊疗和病种的关系
兼顾性能与模型复杂度的平衡
查看更多内容,欢迎访问天池技术圈官方地址:人社大赛算法赛题解题思路分享+第五名_天池技术圈-阿里云天池